Résultats jugés à postériori : Google traduction a fait une phrase qui n’a aucun sens, on est (quand même) content ;
Test sur plusieurs centaines de langues, maximisant la probabilité qu’une marche par hasard ;
On utilise des anagrammes, ce qui maximise encore la probabilité…
Biais de confirmation : ils trouvent « fermier », il y a des images de plantes, on pense que c’est un guide botanique, donc on va dire que ça va dans le bon sens (on ne vous dira pas tous les mots qui n’ont aucun rapport…).
Extrait de l’abstract :
It [l’approche] obtains the average decryption word accuracy of 93% on a set of 50 ciphertexts in 5 languages.
qui semble confirmer que ça marche pour plein de langues (donc pour aucune, désolé).
Tu as lu l’article en entier pour être aussi péremptoire sur l’ensemble du travail ?
Résultats jugés à postériori : Google traduction a fait une phrase qui n’a aucun sens, on est (quand même) content ;
Tu proposes une méthode qui trouve la langue d’un texte encodé et anagrammé, tu le tests sur un corpus de langues connus, tu donnes les statistiques. Tu l’appliques à un texte inconnu, il te sort une proximité avec une langue et le résultat. Problème tu ne parles pas la langue, tu ne vas pas utiliser un outil comme Google Trad (en plus de demandé à un collègue qui parle la langue) pour voir ce que ça donne ? Ces traductions c’est deux paragraphes sur douze pages, entourés de paragraphes où ils sont prudents sur les résultats de l’algorithme sur ce manuscrit.
Test sur plusieurs centaines de langues, maximisant la probabilité qu’une marche par hasard ;
La partie testée sur les centaines de langues c’est l’identification d’une langue d’un texte encodé. Ils montrent juste que l’algorithme donne le bon, (enfin 97%[^stat]), résultat après l’apprentissage.
On utilise des anagrammes, ce qui maximise encore la probabilité…
Ils disent exactement ce que tu viens de dire. Cependant, décoder un texte encodé avec des anagrammes c’est une problématique comme une autre.
Biais de confirmation : ils trouvent « fermier », il y a des images de plantes, on pense que c’est un guide botanique, donc on va dire que ça va dans le bon sens (on ne vous dira pas tous les mots qui n’ont aucun rapport…).
Ils trouvent 5 mots en rapport avec la botanique sur les 72 premiers mots de la section herbier. Et c’est le paragraphe qui suit celui de la traduction de la phrase. A nouveau, ils présentent ça en restant prudent : ça peut n’être qu’une simple coïncidence.
Extrait de l’abstract :
It [l’approche] obtains the average decryption word accuracy of 93% on a set of 50 ciphertexts in 5 languages.
qui semble confirmer que ça marche pour plein de langues (donc pour aucune, désolé).
Un algorithme qui, après apprentissage de 5 langues (sur d’énormes corpus), est capable à partir de 50 textes encodés et anagrammés de 500 mots chacun (10 dans chacune des langues), de trouver la langue de 49 textes sur 50 et d’avoir juste sur le déencodage de 93% des mots, ça ne vaut rien[^stat] ?
Je n’ai fait que parcourir les pages, mais je te trouve assez dur dans ton jugement. Il y a peut-être plein de problèmes (ce n’est pas mon domaine, j’ai du mal à juger le fond) mais pas aussi fort que l’impression que ton message m’a laissé.
[^stat] Je ne sais pas si c’est statistiquement suffisant (je n’ai pas cherché à faire le calcul), je vais faire confiance sur le processus de pair-review (en l’absence de gros doutes et de temps)
Plus que « cette étude », c’est « ce genre d’étude » que je critique. Si tu préfères, j’ai quelques mots-clé qui m’indique une foutaise probable, et là, c’est plutôt allumé. Donc non, je n’ai pas lu l’étude en détail, et j’ai effectivement mal interprété des bouts (notamment le passage sur les 93 %).
Reste que dire qu’on a 5 mots sur 70 pas trop bizarre dans la section herboriste (mettre light, air et fire, j’appelle pas ça « être bon », juste « pas trop bizarre »), ou que « According to a native speaker of the language, this is not quite a coherent sentence. However, after making a couple of spelling corrections, Google Translate is able to convert it into passable English », c’est pas sérieux : un article, c’est plusieurs mois de boulot, tu peux trouver le temps de choper un type qui parle hébreux pour donner un traduction.
Je ne dis pas que l’étude est fausse, je dis qu’elle ne vaut pas d’être analysée en détail plus que la demi heure que j’y ai déjà consacrée.
Et du coup les universités payent des abonnements j’imagine ?
Trois plombes plus tard, j’y repense. Je n’ai pas retrouvé les chiffres pour Springer, avec lequel il y a conflit actuellement, mais je les ai pour Elsevier, qui est l’autre gros éditeur scientifique. C’est 170 millions pour 5 ans, toutes universités confondus, chiffres de 2014.
Et c’est là un éditeur (donc plusieurs revues, mais pas toutes). Il faut au moins le multiplier par 2, avec Springer. On peut comparer ça aux employés : 200 € / personne / an pour Elsevier seul, en comptant tous les employés, et pas uniquement les chercheurs. Ou avec le budget de l’enseignement supérieur et de la recherche, de 27 milliards en 2018, soit 0,13 % uniquement pour Elsevier, sachant que la recherche ne représente qu’une partie du dit-budget.
Un petit commentaire vaguement dans le sujet. Je suis tombé sur un article, dans un journal elsevier payant, où sur la première page figure le texte suivant :
This manuscript has been authored by XXXX under Contract No. XXXX with the U.S. department of Energy. The united States Government retains and the publisher, by accepting the article for publication, acknoledges that the Unisted States Government retains a non-exclusive, paid-up, irrevocable, world-wide license to publish or reproduce the pulished form of this manuscript, or allow others to do so, for Unisted States Government purposes. The department of Energy will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan.
Du coup, ca a une valeur légale de mettre ce texte sur son article ? Parce qu’il me semble qu’en faisant comme ca, on pourrait bénéficier du peer-review, de la visibilité des journaux, tout en ayant une version téléchargeable gratuitement sur son propre portail, non ?
Je sais pas pour les USA, mais en france, vous avez pas un truc du même genre ou les articles doivent être mis en libre accsès après un certain temps ?
Presque. On peut mettre en ligne la version finale d’un article après 6 mois en sciences et 12 mois en SHS.
« Art. L. 533-4.-I.-Lorsqu’un écrit scientifique issu d’une activité de recherche financée au moins pour moitié par des dotations de l’Etat, des collectivités territoriales ou des établissements publics, par des subventions d’agences de financement nationales ou par des fonds de l’Union européenne est publié dans un périodique paraissant au moins une fois par an, son auteur dispose, même après avoir accordé des droits exclusifs à un éditeur, du droit de mettre à disposition gratuitement dans un format ouvert, par voie numérique, sous réserve de l’accord des éventuels coauteurs, la version finale de son manuscrit acceptée pour publication, dès lors que l’éditeur met lui-même celle-ci gratuitement à disposition par voie numérique ou, à défaut, à l’expiration d’un délai courant à compter de la date de la première publication. Ce délai est au maximum de six mois pour une publication dans le domaine des sciences, de la technique et de la médecine et de douze mois dans celui des sciences humaines et sociales.
Bon, je suis super dérangé par une vidéo récente de Lê, sur la surinterprétation.
L’apprentissage automatique n’est pas mon domaine d’expertise, mais on est bien d’accord que l’overfitting ce n’est absolument pas de la surinterprétation ?
Pour moi, l’overfitting (ou surapprentissage, en français), c’est le fait qu’un problème de l’AA est fondamentalement mal posé : on ne peut pas généraliser à partir d’un ensemble de données, parce qu’il y a toujours une infinité de solutions, même avec des hypothèses de régularité. Du coup, l’apprentissage va faire un compromis entre solution générale et solution parfaite, c’est d’ailleurs ce qu’on appelle le dilemme biais-variance. Pas de variance, on sous-apprend, pas de biais, on sur-apprend.
L’interprétation des données, en revanche, est un domaine qui selon moi est complètement indépendant de l’AA, vu qu’un algorithme d’AA, ça n’interprète rien, ça ne fait que classer, regrouper ou prévoir (ou générer, et probablement d’autres que je ne connais pas).
C’est pour ça que ça vidéo m’emmerde pas mal, parce que visiblement il y en a un d’entre nous deux qui n’a pas du tout compris de quoi ça parle le machine learning. :/
Edit : je viens de voir la vidéo suivante. C’est moi ou il se contredit directement sur l’overfitting ? Bon cela dit il finit par répondre à une question similaire à la mienne en fin de vidéo, mais bon, c’est pas convaincant pour moi. Et puis c’est un peu ce que je reproche à ses vidéos en ce moment, il met de plus en plus en avant ses avis persos qui à ma connaissance ne font pas l’unanimité…
Tiens, je mets ça là parce que je ne savais pas où le mettre, mais voici une preuve de l’irrationalité de $e$… écrite en monovocalique en e.
Démence de e
Je présente cette thèse : e est dément.
Je prends x réel et je rejette les n ébréchés. [Les règles permettent x rêvé, de même.] ex est l’ensemble des xn/n! entre n désert et n extrême. Je le représente en ces termes :
ex = 1 + x + x2/2 + x3/3! + …
Bref, ex dépend de x. Mes recherches se resserrent vers l’essence démente de e. Je préfère cerner le renversement de ce réel, entendez l’élément 1/e = e-1. C’est en effet le même thème. Je me permets de relever le sens de cet élément :
1/e = 1/2 - 1/3! + 1/4! - 1/5! + …
Cette sentence révèle le bercement des termes : être élevé, descendre, se relever, redescendre, etc. Et en même temps, ces termes désenflent éternellement. Bref, j’entends cette belle règle entre 1/e et ces réels près de 1/e :
0 < 1/e - [1/2 - 1/3! + … - 1/(2n-1)!] < 1/(2n)!
Je mets (2n-1)! en présence de ces termes, et l’effet en est :
0 < (2n-1)!/e - N < 1/(2n).
Relevez cette preste pensée : N est net, préservé. Je répète : N n’est ébréché ! Et vers l’extrême dextre, 1/(2n) n’excède 1/2. C’est certes très près de l’événement recherché.
Je tente de prétendre : 1/e n’est dément. [En termes lestes : e est sensé.] Je prends n très élevé, je mets (2n-1)! en présence de 1/e, et cette recette le rend exempt de reste. Bref, je déterre le réel net (2n-1)!/e - N, et je le serre entre 0 et 1/2. C’est fêlé ! Et c’est le terme de l’errement : 1/e est dément, et e l’est de même.
Pour moi, l’overfitting (ou surapprentissage, en français), c’est le fait qu’un problème de l’AA est fondamentalement mal posé : on ne peut pas généraliser à partir d’un ensemble de données, parce qu’il y a toujours une infinité de solutions, même avec des hypothèses de régularité. Du coup, l’apprentissage va faire un compromis entre solution générale et solution parfaite, c’est d’ailleurs ce qu’on appelle le dilemme biais-variance. Pas de variance, on sous-apprend, pas de biais, on sur-apprend.
L’interprétation des données, en revanche, est un domaine qui selon moi est complètement indépendant de l’AA, vu qu’un algorithme d’AA, ça n’interprète rien, ça ne fait que classer, regrouper ou prévoir (ou générer, et probablement d’autres que je ne connais pas).
C’est pour ça que ça vidéo m’emmerde pas mal, parce que visiblement il y en a un d’entre nous deux qui n’a pas du tout compris de quoi ça parle le machine learning. :/
Edit : je viens de voir la vidéo suivante. C’est moi ou il se contredit directement sur l’overfitting ? Bon cela dit il finit par répondre à une question similaire à la mienne en fin de vidéo, mais bon, c’est pas convaincant pour moi. Et puis c’est un peu ce que je reproche à ses vidéos en ce moment, il met de plus en plus en avant ses avis persos qui à ma connaissance ne font pas l’unanimité…
Il a bien raison. Le machine learning consiste simplement a approximer une fonction $f: X \to Y$ inconnue via $h: X \to Y$. Pour cela il faut 1) des hypotheses ou le model-space$H$ dans lequel on suppose que $h$ vit, puis des donnees desquelles ont peut construire ou choisir $h$ dans $H$ en s’aidant d’un critere de minimisation soit naturellement issu du probleme soit plus generique. La methode pour construire ou choisir $h$ est l’algorithme de Machine Learning.
Le surapprentissage ne provient pas du fait que le probleme est mal pose mais que soit:
le model space $H$ est trop large ou trop restrictif (par exemple, chercher des polynomes de degres N pour chercher une fonction $f$ polynomiale de degre M « N,
les donnees dont on dispose ne sont pas representatives de l’espace $X$. En effet, l’erreur de generalisation est donnee par $\int_X ||f(x) - h(x)||\mu(x)dx$ ou $\mu$ est la distribution de probabilite de rencontrer $x$. Si par exemple tu cherches a creer un modele pour classifier les animaux que tu peux voir a Paris, et que le jeu d’entrainement ne contient aucun pigeon (l’animal, pas le parisien) mais que des girafes et animaux de la jungle dont il est peu probable qu’en pratique ils apparaissent, ton model aura une grande erreur de generalisation. Le probleme en lui meme n’est pas mal pose.
Il y a un autre probleme qui est celui de la representation des donnees, que je ne detaille pas ici, mais qui n’est lui aussi pas en lien avec le fait que le probleme soit bien ou mal pose.
Le dilemme biais-variance c’est la traduction des mauvaises hypotheses, i.e. le point 1) mais ce n’est pas tout l’overfitting.
D’ailleurs en general, accumuler beaucoup de donnees (ce qu’on appelle vulgairement le BigData) permet de contrer l’effet de l’overfitting du a des hypotheses trop fortes.
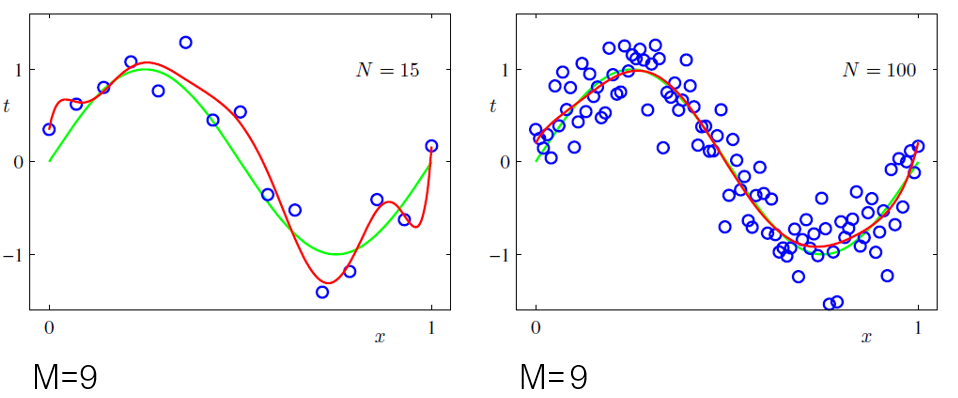
Voici un exemple de mon cours de ML:
Pour le visualiser, il suffit de prendre un polynome de degres 3, et prend respectivement 15 et 100 points sur lesquels on ajoute un bruit gaussien. Fait une regression polynomiale de degres disons 9 sur les deux jeux de donnees. Tu verras qu’avec 15 points, c’est tres loin de ressembler au polynome de degres 3 mais qu’avec 100 points, le polynome de degres 9 approche tres bien celui de degres 3.
Il n’y a plus d’overfitting et pourtant les hypotheses de notre model ne sont pas les bonnes.
Je pense que ce qui te gene c’est la francisation du terme overfitting. L’interpretation au sens ou tu le comprends, je pense qu’il s’agit plutot du terme "explainability", c’est a dire la capacite du modele a expliquer ses choix de classification, prediction, etc.
Effectivement, j’avais raté un sacré paquet de choses, et je comprends mieux le message de la vidéo. Bon, du coup j’aime toujours pas, mais au moins maintenant je sais pourquoi.
Je sais que Coq l’utilise et en sont très satisfait. Pour le projet de notre équipe, c’est encore une question ouverte de savoir si on va l’utiliser ou non.
Une fois n’est pas coutume, je vais citer une mini-vidéo publiée sur twitter.
On parlait dans un billet du fait que se moquer était contreproductif par rapport aux croyances non scientifiques. Ça permet parfois de montrer à quel point un argument est moisi. Ici, à propos du récent complot sur la neige en plastique (version courte : si vous tentez de faire fondre de la neige avec un briquet, vous aller noircir la neige, mais elle en va pas fondre, donc elle est en plastique). Le gruyère ne fondra pas non plus, et va aussi noircir. Donc il est en plastique. En se moquant, on montre que la démarche originelle n’était pas fondée pour démontrer l’hypothèse.
Alors je t’invite à regarder la vidéo de Monsieur Phi qui explique pourquoi Hawking se trompait sur ce point. D’ailleurs, tu le dis toi-même : cela relève davantage de l’opinion que du fait. Rien de très objectif dans tout ça.
Hawking était un grand physicien, mais il n’était pas un philosophe.
Il y a un point que je trouve intéressant dans cette vidéo : il ne justifie pas que, en tant que scientifique, je doive me renseigner sur l’épistémologie. Il critique ceux qui pensent ça, cite de grands savants qui le pensent, renvoie vers de longs bouquins ou de longues vidéos sur le sujet, mais ne prend pas deux minutes pour nous dire en quoi c’est important. Il passe la plus grande partie de la vidéo à défendre sa discipline, et critiquer ceux qui disent qu’il n’est pas utile de s’y intéresser.
De fait, ce n’est pas étonnant qu’aucun scientifique ne s’y intéresse. Si on prend en compte la petite pique « l’épistémologie ne s’est pas arrêté avec Popper », je connais très exactement deux personnes qui m’ont parlé d’épistémologie récente, à savoir Holosmos et Mr Phi. Et c’est un sujet qui m’intéresse, je n’ai juste pas encore pris le temps de lire un livre complexe de plusieurs centaines de pages sur le sujet.
Au quotidien, je bataille déjà pour trouver des études reproductibles ou avec des statistiques dans mon domaine, ou convaincre mes collègues que ce n’est pas parce que leur modèle donne de bons résultats que le monde se comporte comme le dit leur modèle, alors j’ai l’impression que déjà, si les gens allaient jusqu’à Popper, ce serait bien.
Il y a dans son discours une forme qui me dérange beaucoup ; une injonction que son domaine est important, sans jamais l’argumenter, ce qui est assez gênant pour quelqu’un s’opposant aux philosophes aux phrases creuses. Ce qui n’empêche que presque tous les scientifiques que je connais se contrefiche de l’épistémologie.
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte