Xenos, ne t'inquiète pas, je connais bien le language et je l'ai utilisé pendant longtemps. Sauf que :
la norme est maintenant aux templates. Ça fait du code moche et difficile à maintenir d'avoir de la logique et des données (ce qu'il y a à afficher) en mêlées ensemble. Pas obligé d'utiliser du MVC, mais rien que séparer le HTML du PHP ça aide.
c'est vrai que c'est très commun comme symbole le point pour de la concaténation. Vu comment PHP est laxiste sur les opérations, je ne comprends pas pourquoi il n'utilise pas le + pour additionner deux strings. "foo" + "bar" === 0. Logique. Et deux symboles difficiles à accéder pour appeler une propriété ou une méthode sur une instance, ce n'est pas très logique.
Ce n'est moins logique que le C, puisque l'opérateur -> vient de là ((*this).property = this->property). PHP est laxiste sur les cast plutôt que les opérations: "0" + "4" = 4 (auto-cast de PHP) ou 0 (pas d'auto-cast)?
Pour ce qui est de séparer template et coeur de code, oui, c'est clairement une bonne pratique. Après, pourquoi vouloir s'embêter à apprendre deux langages différents pour cela, et à les faire communiquer entre eux (c'est le plus ch*ant surtout)? L'avantage du PHP réside justement dans le fait d'avoir son coeur de code et son code template qui communiquent parfaitement, et d'avoir ainsi l'auto-complétion (et le typehinting) qui vont avec.
<< Mais je diverge là, j'vais essayer de ne pas prendre les mêmes habitudes ici que sur JeuWeb >>
Tu peux faire du web sémantique avec n'importe quel framework web. La technologie sous-jacente, celle qui sert à générer les pages web, n'a rien à voir avec le web sémantique. Ocsigen n'a rien à voir avec le web sémantique. Django non plus. PHP ou JavaScript non plus. Le web sémantique, c'est le web qui inclut des données structurées, généralement des données RDF-like qu'on inclut dans les pages sous forme de microdonnées/microformats, par exemple schema.org.
Tiens, un exemple, cette page web appartient au web sémantique. Son code source est immonde et ne respecte pas du tout la sémantique HTML, ce qui ne pose pas de problème puisque le web sémantique n'a pas grand chose à faire de la sémantique HTML. Si tu prends n'importe quel outil du web sémantique, j'en ai pris au pif en cherchant sur google, celui-ci, et que t'y mets l'URL en question, tu verras que cette page fait bien partie du web sémantique : http://microdata-extractor.improbable.org/extract/?url=http%3A%2F%2Fbeat.doebe.li%2Fbibliothek%2Fp00403.html En effet elle contient au moins une entité sémantique : cette entité est une Person représentée dans l'ontologie schema.org, elle a pour propriétés un nom, une description, une photo et une date de décès.
Aussi, je veux pas t'embêter ou m'acharner, mais :
Au contraire de @felko, je te déconseille vivement d'utiliser Elm pour autre chose que pour cela est fait: faire du FRP. C'est vraiment très mauvais pour construire du Web sémantique.
Elm n'est plus FRP depuis quelques quelques temps. Plus besoin de comprendre ce concept pour faire de l'Elm, il n'est plus utilisé dans Elm. Le modèle actuel d'Elm est un modèle de signaux et de souscriptions. En gros tu créés une souscription, et tu envois des signaux. Elm a abandonné le FRP, parce qu'au final c'était pas une si bonne idée.
De fait, je te déconseille d'utiliser autre chose que JavaScript en front-end, surtout depuis ES6
Je ne comprends pas ce point de vue. Quel rapport entre ES6 et l'utilisation qui est faite de JS ? ES6 a surtout apporté du sucre syntaxique à JS, et ajouté 2-3 éléments de syntaxe pour clarifier le scoping et continuer à faire évoluer le langage en direction de la prog fonctionnelle (malgré une grosse bourde : l'introduction du mot-clé class qui fait croire à beaucoup que la POO JS a un quelconque rapport avec les langages OO class-based comme Java, Python, Ruby, C++, PHP, etc). ES6 n'est pas mieux ou pire qu'ES5 pour faire du front-end, pas mieux ou pire qu'ES5 pour faire du back-end. C'est juste une nouvelle version du langage, pas mal mieux que la précédente, c'est tout. Ça ne change rien à l'emploi qu'on fait de JS.
Il y a bien un langage qui semble convenir à la situation mais je ne l'ai pas encore testé, c'est Elixir avec le framework Phoenix. http://www.phoenixframework.org/
Yep, Elixir et Phoenix sont super, je suis assez fan. Je dirais pas que c'est "basé" sur BEAM, la VM d'Erlang. Elixir est compilé en bytecode Erlang qui est interprété par BEAM. Elixir est un langage fonctionnel dynamique très agréable à utiliser, très propre, très bien conçu. Phoenix est idéal pour remplacer par exemple Node ou Tornado, donc pour faire du temps réel et gérer des millions de websockets, mais aussi simplement pour créer un site dynamique comme le permettent PHP, Python, etc.
Tu peux faire du web sémantique avec n'importe quel framework web. La technologie sous-jacente, celle qui sert à générer les pages web, n'a rien à voir avec le web sémantique. Ocsigen n'a rien à voir avec le web sémantique. Django non plus. PHP ou JavaScript non plus. Le web sémantique, c'est le web qui inclut des données structurées, généralement des données RDF-like qu'on inclut dans les pages sous forme de microdonnées/microformats, par exemple schema.org.
Effectivement, ça a certainement un sens marketing que je ne connais pas; je l'utilise au sens A.1 (III) du TLFi, « qui a du sens ». Cela requiert une certaine forme de contextualisation, ce que notamment XML (et par extension HTML) sait bien faire. Au contraire, dans un cas général, c'est plutôt gênant en JavaScript. Par exemple, on trouve Please login de la page d'exemple elm-hedley dans la ligne de 1077 caractères que j'ai abrégée ci-dessous. On ne peut pas en déduire d'information.
Elm n'est plus FRP depuis quelques quelques temps. Plus besoin de comprendre ce concept pour faire de l'Elm, il n'est plus utilisé dans Elm. Le modèle actuel d'Elm est un modèle de signaux et de souscriptions. En gros tu créés une souscription, et tu envois des signaux. Elm a abandonné le FRP, parce qu'au final c'était pas une si bonne idée.
D'accord, merci pour la correction. Mais ça ne change pas mon point principal.
Je ne comprends pas ce point de vue. Quel rapport entre ES6 et l'utilisation qui est faite de JS ? ES6 a surtout apporté du sucre syntaxique à JS, et ajouté 2-3 éléments de syntaxe pour clarifier le scoping et continuer à faire évoluer le langage en direction de la prog fonctionnelle (malgré une grosse bourde : l'introduction du mot-clé class qui fait croire à beaucoup que la POO JS a un quelconque rapport avec les langages OO class-based comme Java, Python, Ruby, C++, PHP, etc). ES6 n'est pas mieux ou pire qu'ES5 pour faire du front-end, pas mieux ou pire qu'ES5 pour faire du back-end. C'est juste une nouvelle version du langage, pas mal mieux que la précédente, c'est tout. Ça ne change rien à l'emploi qu'on fait de JS.
J'ai du mal à voir en quoi tu ne comprends pas ce que je veux dire. Un petit extrait de vieux JavaScript que l'on peut encore trouver en cadeau sur certains sites ?
functionSearchItem(txt){// txt contient le texte de la recherchetxt=unescape(txt);txt=txt.replace(/\+/g," ");varn=tjs_base.nb_item;varindice=-1;if(txt=="Saisir un mot clé"){alert("Entrez un mot pour la recherche");}else{document.forms["tjs_search"].elements["mot"].value=txt;varZ="";varnb=0;for(vari=0;i<n;i++){if(tjs_base[i].cle.toUpperCase().indexOf(txt.toUpperCase(),0)!="-1"){Z+="<A target='"+tjs_base.target+"' href='"+tjs_base[i].page+"'>"+tjs_base[i].desc+"</A> <SMALL>("+tjs_base[i].page+")</SMALL><BR>"nb++;}}if(nb>0){if(nb==1){Z="Un résultat trouvé pour la recherche sur [<B>"+txt+"</B>] : <BR>"+Z;}else{Z=nb+" résultats trouvés pour la recherche sur [<B>"+txt+"</B>] : <BR>"+Z;}}else{Z="Aucun résultat pour la recherche sur [<B>"+txt+"</B>]<BR>Vérifiez l'orthographe ou essayez un autre mot clé !";}document.write(Z);}}functionTJS_Search(f){if(f.mot.value!=""){f.submit();}}functionTJS_PrintResult(){varurl=document.location.href;if(url.indexOf("?mot=",0)>0){varmot=url.substring(url.indexOf("?mot=",0)+5);SearchItem(mot);}}
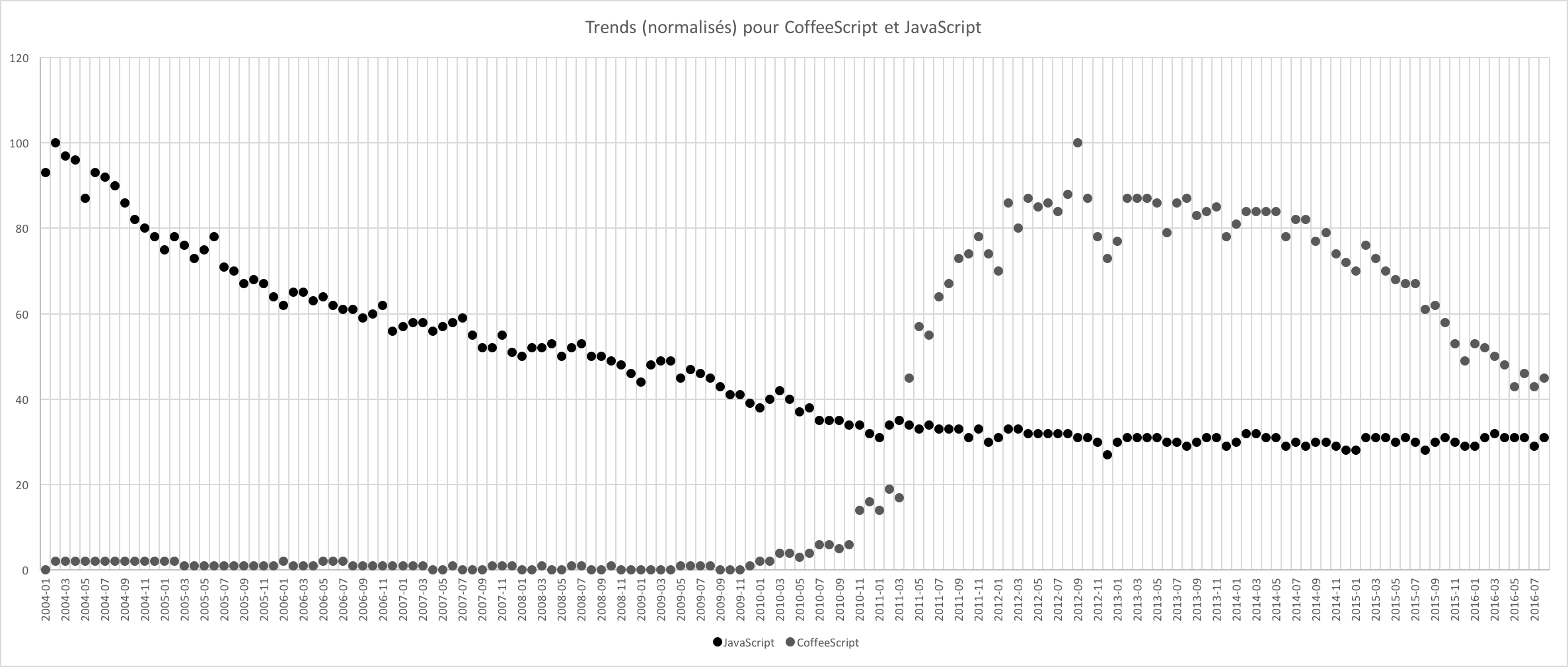
Alors certes, il y a la faute du développeur, mais le langage s'est considérablement modernisé au cours des dernières années. Des langages comme CoffeeScript et, à mon avis, la volonté de compiler d'autres langages vers du JavaScript n'est pas à prendre innocemment. J'ai graphé les recherches de JavaScript (pour avoir une référence) contre CoffeeScript depuis Google Trends.
Trends JS/CS
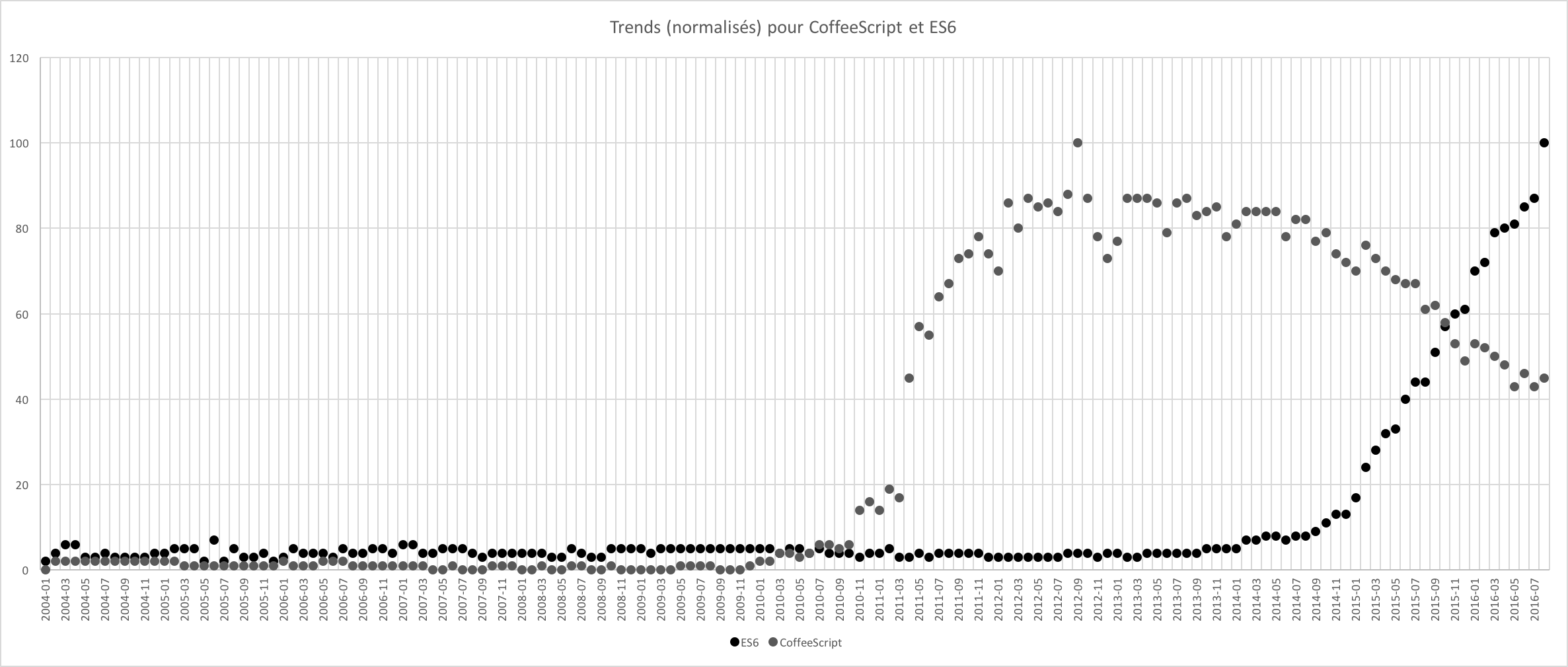
En regardant vite fait, on voit tout de même qu'il y a une baisse de popularité assez nette pour CoffeeScript, alors que JavaScript reste constant depuis trois ans. Deux possibilités, naïvement: soit CoffeeScript devient mauvais, soit il n'intéresse plus, parce que JavaScript a introduit des éléments qui satisfont les utilisateurs de CoffeeScript. J'ai juste graphé ES6/CoffeeScript.
Trends ES6/CS
J'y connais rien en statistique et en traitement de données, mais j'ai l'impression qu'il y a une vague correlation entre les deux. D'où le fait que je pense que ça séduit plus de monde aujourd'hui, et qu'il y a pas trop de raisons d'utiliser autre chose que JavaScript pour faire du front.
Tu peux faire du web sémantique avec n'importe quel framework web. La technologie sous-jacente, celle qui sert à générer les pages web, n'a rien à voir avec le web sémantique. Ocsigen n'a rien à voir avec le web sémantique. Django non plus. PHP ou JavaScript non plus. Le web sémantique, c'est le web qui inclut des données structurées, généralement des données RDF-like qu'on inclut dans les pages sous forme de microdonnées/microformats, par exemple schema.org.
Effectivement, ça a certainement un sens marketing que je ne connais pas; je l'utilise au sens A.1 (III) du TLFi, « qui a du sens ». Cela requiert une certaine forme de contextualisation, ce que notamment XML (et par extension HTML) sait bien faire. Au contraire, dans un cas général, c'est plutôt gênant en JavaScript. Par exemple, on trouve Please login de la page d'exemple elm-hedley dans la ligne de 1077 caractères que j'ai abrégée ci-dessous. On ne peut pas en déduire d'information.
C'est pas un sens marketing, c'est un sens informatique. Dans le contexte de l'informatique, le terme web sémantique a un sens précis que j'ai expliqué dans mon post. C'est le sens donné par wikipedia, par le W3C, par les meilleures conférences académiques à ce sujet comme ISWC, par tous les papiers scientifiques à ce sujet qu'on peut trouver, exemple. Dans un contexte informatique, quand on dit web sémantique, ça a un sens précis, et c'est pas du bluff marketing ou autre bêtise, c'est un champ de recherche académique à part entière et ça a des applications et implications industrielles très sérieuses. schema.org est par exemple un effort conjoint de Google, Microsoft, Yahoo et Yandex pour pousser les gens qui font du web à ne pas seulement produire de l'HTML mais à contribuer au web sémantique en y incluant des données sémantiques.
J'aimerais aussi dire que ces questions de contenus dynamiques générés dans le browser deviennent assez marginales. Il est évident que depuis 3-4 ans et l'avènement des single-page web apps, on a de moins en moins de contenu généré directement dans l'HTML de la page que ton browser charge en premier. Mais l'impact de cette approche en terme de 'crawlabilité' ou d'accessibilité des pages web est en chute violente. Google avec Angular et Angular 2, Facebook avec React, les autres avec Ember, Backbone ou Meteor… les approches web component, l'avènement du shadow DOM, les progressive web apps… Ces technologies forcent à produire de l'HTML valide et encouragent et aident énormément à respecter la sémantique des balises HTML. Si ces choses produites et encouragées par les gens qui vivent du crawlage du web nuisaient à une compréhension des pages web à un niveau sémantique, on n'en serait pas là. Même si les pages web sont de plus en plus des coquilles vides (shells) chargeant et générant (presque) tout l'HTML et le CSS à coup de JS, la qualité du code produit et la capacité technique à les analyser et à en extirper des infos deviennent extraordinaires. Comme je le disais, des pans entiers de la recherche académique s'y consacrent depuis 15 ans. Quand on parle d'Information Retrieval ou de Semantic Web, c'est notamment de ça dont il s'agit.
C'est dans ce contexte d'information retrieval que le web sémantique prend d'ailleurs tout son sens, et c'est la raison pour laquelle les grands moteurs de recherche ont commencé il y a 4-5 ans à pousser en direction du web sémantique, concept datant pourtant de 2001 (? sauf erreur hein, Tim Berners-Lee a posé les bases du web sémantique il y a 15 ans). Microsoft pour Bing, Yahoo pour son moteur de recherche de l'époque, sans surprise Google et Yandex dont c'est le business principal.
Et l'idéal d'avoir des pages web sous forme de documents XML a fait long feu. XHTML par exemple, la variante XML-valid d'HTML, ça a été une mode pendant 3-4 ans et c'est complètement mort depuis, plus personne n'utilise ça, le XML sur le web est littéralement en friche depuis bien des années. HTML n'a jamais vraiment été du XML, malgré la tentative XHTML qui justement ne s'appelait pas HTML pour ne pas porter à confusion.
J'ai du mal à voir en quoi tu ne comprends pas ce que je veux dire.
Ouais, au temps pour moi, j'avais interprété ta phrase complètement différemment, j'ai cru que tu disais qu'il vaudrait mieux éviter d'utiliser JS ailleurs qu'en front-end, surtout depuis ES6. Mea culpa, j'ai mal compris ton message.
Après je nuancerais un peu le propos. Je pense que des alternatives comme TypeScript ont énormément d'intérêt. (Principalement parce qu'elles permettent d'avoir du typage statique et de la transpilation vers ES5 sans avoir à mettre en place plein d'outils, ce qui en fait un gros avantage sur Flow par exemple. Perso j'utilise Flow pour le typage statique et Babel pour stripper les annotations de type et transpiler vers ES5, mais je connais très bien ces outils et je comprends très bien que ça puisse rebuter des tas de gens d'avoir à mettre en place tout ça pour écrire un peu de JS, en front comme en back.)
Connectez-vous pour pouvoir poster un message.
Connexion
Pas encore membre ?
Créez un compte en une minute pour profiter pleinement de toutes les fonctionnalités de Zeste de Savoir. Ici, tout est gratuit et sans publicité.
Créer un compte


 >>
>>