C'est bon ? Vous avez un graphe joli tout plein ? Il attend sagement dans la RAM que vous vous occupiez de lui ?
Vous êtes ici pour pouvoir - enfin ! - programmer vos premiers algorithmes de graphe.
Vous allez apprendre à explorer la bébête, avec le DFS, le BFS et l'exhaustif. Et avec la foultitude d'exemples que je vous donnerai, je vous promets que vous ne tarderez pas à découvrir le nombre incroyable de problèmes que ces simples algorithmes résolvent.
Préparez vous à plonger profondément1 dans l'univers des graphes.
-
Vous comprendrez plus tard. ↩
Le parcours en profondeur et le labyrinthe
Les pyramides
Aaaah l'Egypte ! Le soleil, le sable, le Nil ! Le Sphinx et son nez ! Les pyramides, leurs labyrinthes, et leurs… euh… labyrinthes.
Fidèle à la tradition familiale vous êtes devenu un pilleur de tombeaux. Vous n'êtes pas sans ignorer que la chambre funéraire recèle maints trésors, que vous avez hâte de vous approprier afin d'ouvrir le magasin de guimauve dont vous rêvez depuis votre enfance.
Sauf qu'aujourd'hui vous êtes tombé sur une pyramide très particulière, avec de nombreux carrefours… mais certains mènent à des pièges abominables, tellement abominables que je n'ose pas les décrire ici !
Vous disposez d'une carte du labyrinthe (remettant ainsi en cause l'utilité de ce dernier). Soucieux de ne pas prendre de risques superflus, vous confiez à votre ordinateur la dure tâche de trouver un itinéraire fiable.
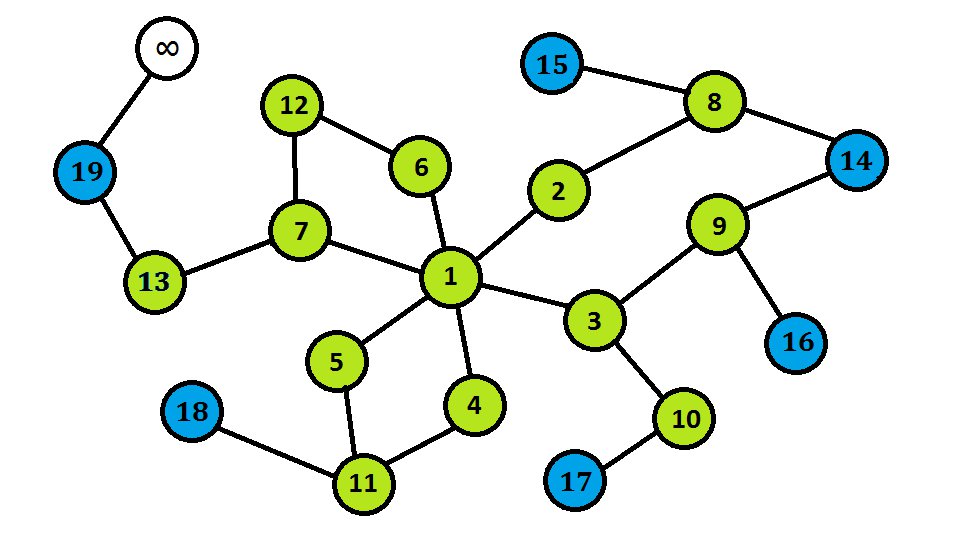
Voici le plan :
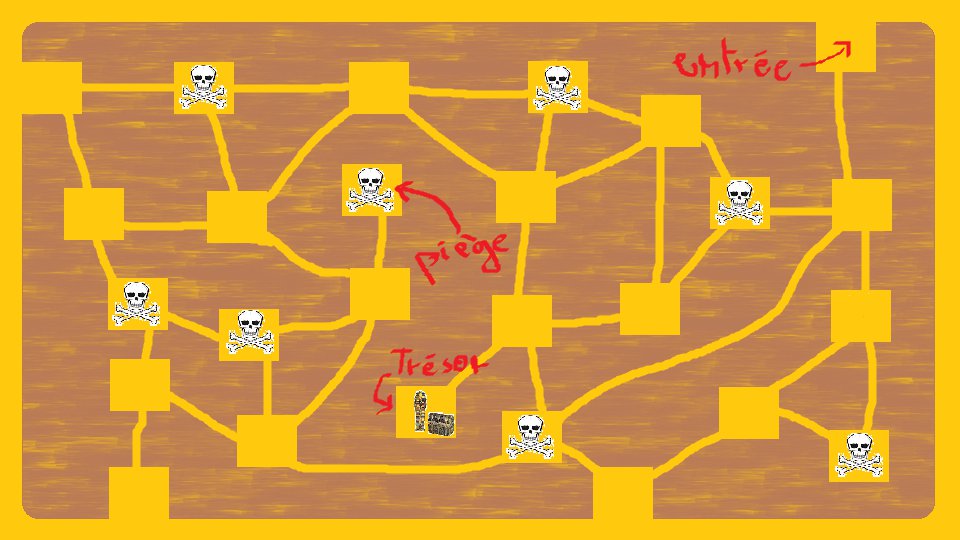
Exercice : trouvez le graphe associé à ce problème. Trouvez ses caractéristiques principales. Trouvez quelle question on se pose sur ce graphe. Puis choisissez la structure de données qui vous semble la plus appropriée à la résolution du problème !
Commençons par le graphe.
Il apparaît clairement que chaque couloir est une arête.
Par conséquent les nœuds seront des intersections.
Certains nœuds sont particuliers.
Les entrées du labyrinthe : c'est de l'une d'entre elles que commence le chemin.
La chambre funéraire : c'est l'aboutissement d'un chemin (s'il existe).
Les salles piégées posent problème : elles existent mais nous ne pouvons pas les traverser. Deux solutions.
- soit on ajoute ces nœuds particuliers au graphe, en précisant bien qu'ils sont piégés pour que l'algorithme les ignore (compliqué et désagréable à implémenter, plein de cas particuliers à gérer).
- soit on les ignore purement et simplement lors de la construction du graphe, comme s'ils n'en faisaient pas parti (plus simple, plus propre).
Nous choisirons donc la seconde solution.
Et retenez de cela qu'il ne faut pas s'encombrer de superflu (un sérieux coup de pied dans les fesses de la société de consommation, pas vrai ?), la simplicité, l'expressivité et la concision sont les mots d'ordre du développeur.
Cela vous évitera de tristes après-midis de débogage.
Passons aux caractéristiques du graphe.
- Ce graphe est non orienté : vous pouvez traverser un couloir dans les deux sens, et même sur les mains si ça vous plaît.
- Ce graphe est cyclique, car certains itinéraires tournent en rond (ah les fourbes !).
- Ce graphe n'est pas pondéré. Certains objecteront qu'on peut associer à chaque couloir sa longueur, le coefficient de dureté du sol, l'âge de sa construction ou que sais-je encore. C'est vrai. Sauf qu'on s'en fout. On est pas ici pour trouver le chemin le plus respectueux pour vos pieds, donc ne nous encombrons pas de ces broutilles. Pas de superflu.
- Ce graphe n'est pas connexe : vous ne pouvez pas accéder à n'importe quel endroit depuis n'importe quel autre endroit. On dénombre 2 composantes connexes d'ailleurs.
- Ce graphe est creux : on a seulement 17 arêtes pour 18 nœuds (après suppression des nœuds piégés et des couloirs qui leur sont associés).
On choisira donc la liste d'adjacence pour stocker ce graphe !
Pour finir voici la question que l'on se pose.
Existe-t-il un chemin entre une entrée et la chambre funéraire ?
Autrement dit, la chambre funéraire est-elle connexe à au moins une entrée ?
Quel est ce chemin (ou l'un de ces chemins) ?
Le parcours en profondeur
Le DFS est la méthode la plus simple pour parcourir un graphe. Elle fonctionne sur tout type de graphe, cyclique ou non,orienté ou non, etc.
En langage naturel ça donne : je pars d'un endroit que je ne connais pas, je me dirige vers d'autres endroits que je ne connais pas, et quand je suis bloqué je fais demi-tour jusqu'à retrouver un chemin que je n'ai pas encore parcouru. Assez instinctif pas vrai ?
C'est la méthode que l'on utilise lorsqu'on est perdu, ou lorsqu'on visite un bâtiment : on essaie plusieurs chemins, et lorsqu'on est coincés on fait demi-tour jusqu'à la précédente intersection.
Voici sa description sous forme d'algorithme :
- 1) Je cherche un nœud non visité.
- 2) Pour visiter ce nœud, je marque le nœud comme visité.
- 3) Je prends l'un de ses voisins :
- si le voisin a déjà été visité je l'ignore et je cherche un autre voisin
- si le voisin n'a pas encore été visité, je le visite
- si tout les voisins ont été visité, je reviens au nœud précédent, et je ré-applique le 3)
- 4) Je reprend le 1) tant qu'il reste des nœuds non visités
Vous avez remarqué ? Une boucle (de 4 à 1) englobe la totalité de l'algorithme. Cette condition d'arrêt (tant qu'il reste des nœuds non visités) nous assure que l'entièreté du graphe sera exploré.
Il n'y a pas que ça : pour visiter un nœud, il faut aussi visiter l'un de ses voisins non visité. Un concept qui se renvoie à lui même pour se définir, ça ne vous fait penser à rien ? Mais si, la récursivité bien sûr !
Passons au pseudo-code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | Procedure explorer(Graphe G)
{
Pour chaque noeud N de G
Si N non visite
DFS(G, N)
}
Procedure DFS(Graphe G, Noeud N)
{
Marquer N comme visite
Pour chaque voisin V de N
Si V non visite
DFS(G, V)
}
|
Remarquez une chose : la fonction explorer fera autant d'appels à DFS qu'il existe de composantes connexes distinctes, dans un graphe non orienté. Le DFS est donc un bon moyen de retrouver les composantes connexes d'un graphe non orienté.
Si nous ne marquions pas les nœuds comme étant visités, nous nous mettrions à tourner en rond, dans le cas d'un graphe cyclique. Cela entraînerait donc des appels récursifs infinis, et notre programme ne se terminerait jamais ! Pour cette raison, le DFS est l'algorithme le plus adapté à la détection de cycles.
Vous comprenez maintenant l'origine du nom DFS : l'algorithme descend en profondeur dans le graphe, avant de faire demi-tour.
Sur le graphe ci-dessous l'ordre d'exploration pourra donc être : A - B - D - F - E - C - G

Voyons le problème sous un autre angle, et dessinons les arêtes empruntées par le DFS :
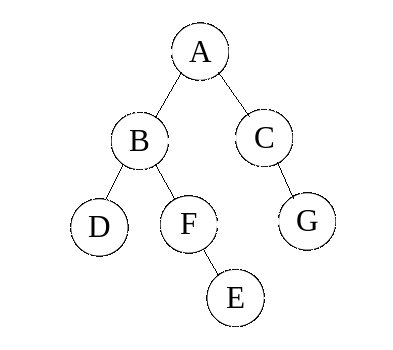
Cela ne vous fait penser à rien ? C'est un arbre !
En effet, ce graphe ne comporte pas de cycles (puis que le DFS ne doit pas boucler).
Et on s'aperçoit que le DFS, de nature récursive, se prête bien au parcours de cette structure de données récursive : pour explorer un arbre, on explore sa racine puis les sous-arbres qui le composent.
Jetons un petit coup d’œil à la complexité en temps de cet algorithme.
On remarque que chaque nœud ne sera traité qu'une seule fois, et on a tôt fait de conclure (à tort) qu'il est en $O(N)$.
Sauf que… pour chaque nœud, on itère sur tout ses voisins (qu'un appel récursif soit fait dessus ou non).
D'où une complexité en temps de $O(N+A)$. On voit donc ici que le nombre de nœuds est fonction - de façon assez évidente - de la vitesse d'exécution, mais que la densité du graphe a elle aussi un rôle très important.
La complexité en mémoire dépend du nombre d'appels récursifs (qui font grossir la pile), et il peut y en avoir autant que de nœuds dans le graphe. La complexité en mémoire est donc $O(N)$. Le pire des cas correspond à un graphe sous la forme d'une liste de nœuds chaînés les uns à la suite des autres, là où la profondeur d'appel est maximale.
Le DFS tel que je vous l'ai présenté ici est assez "nu" mais il va sans dire qu'avec quelques modifications il est en mesure de résoudre un grand nombre de problèmes (ici déterminer si deux nœuds sont sur la même composante connexe). Nous verrons cela dans les chapitres suivants.
Que le DFS soit de nature récursive est autant un avantage qu'un inconvénient. Un avantage car beaucoup plus simple à lire, à écrire et à déboguer (lorsqu'on est à l'aise avec la récursivité). Mais un inconvénient car chaque appel récursif fait grossir la pile d'appel, qui possède une taille limitée dépendant de votre langage, de votre OS et de votre compilateur/interpréteur (souvent 1000 mais n'en faites pas une généralité). Si votre graphe est trop gros vous pourriez rencontrer d'importants problèmes de mémoire. La solution consiste à ré-implémenter le DFS en itératif en simulant la pile d'appel grâce à une pile LIFO.
Luke, je suis ton père
Normalement, vous disposez d'assez d'informations pour résoudre le problème à présent. Il suffit de modifier un peu la fonction DFS.
Ne regardez pas la solution avant d'avoir bien cherché !
Bon, récapitulons : si ce chemin existe, après l'avoir parcouru, il faut savoir le retrouver.
Remarquons deux choses : ce chemin, quel qu'il soit, reste le même quelque soit le sens dans le quel on l'emprunte; en outre, chaque nœud n'est visité qu'une et une seule fois, donc il n'existe qu'un seul moyen de parvenir à lui dans le DFS.
C'est directement en lien avec l'observation de tout à l'heure : le DFS explore un arbre, donc chaque nœud n'a qu'un seul père.
Il suffit donc de remonter dans l'arbre, depuis la chambre funéraire jusqu'à la racine (c'est à dire le premier appel à la fonction DFS sur cette composante connexe).
Et pour cela rien de plus simple : il faut que chaque nœud retienne qui est son père.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | Fonction trouverChemin(Graphe G)
{
Pour chaque noeud N de G
pere[N] = NUL
explorer(G)
Noeud chemin[]
Noeud courant = chambreFuneraire
Tant que courant != NUL // == Tant qu'on est pas sorti
chemin.ajouter(courant)
courant = pere[courant]
Renvoyer inverse(chemin) // car le chemin est reconstruit à l'envers
}
Procedure explorer(Graphe G)
{
Pour chaque noeud N de G
Si N non visite et N est une entree
pere[N] = NUL
DFS(G, N)
}
Procedure DFS(Graphe G, Noeud N)
{
Marquer N comme visite
Pour chaque voisin V de N
Si V non visite
pere[V] = N
DFS(G, V)
}
|
Si ce chemin existe il sera trouvé. Sinon, la fonction trouverChemin renverra la liste singleton [NUL] pour signifier l'absence de chemin.
Ci-dessous, un exemple de solution (pas forcément la plus courte).
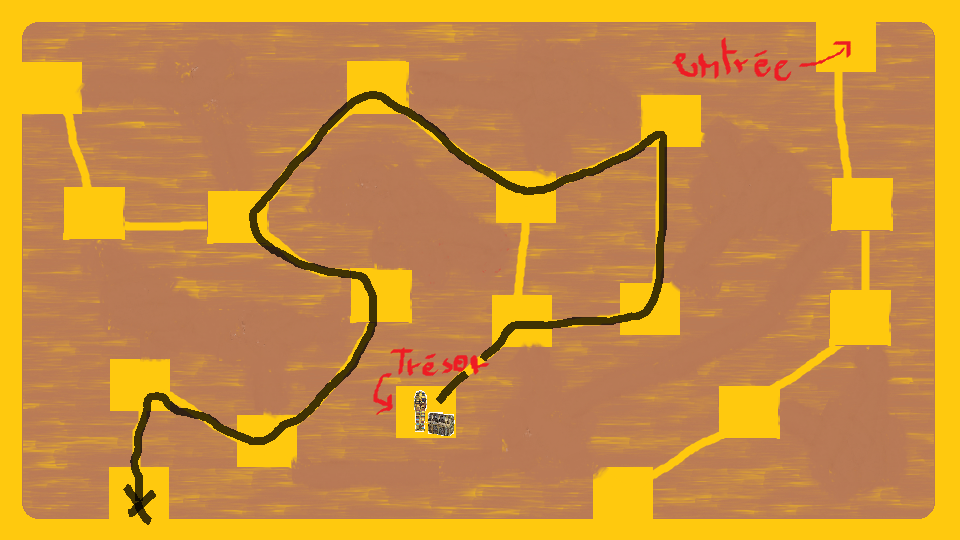
Et voilà ! Vous avez trouvé votre chemin. Mais n'oubliez pas : il y a une différence entre connaître le chemin et arpenter le chemin.
Le parcours en largeur et le buzz
Big Buzz
Vous venez d'achever l’œuvre de votre vie : une vidéo si stupide qu'elle va rencontrer un succès incroyable.
Elle va faire le buzz, vous le savez : quiconque la voit ne pourra pas s'empêcher de la partager juste après. Personne n'y échappera, subjugué par tant de bêtise humaine.
Vous voulez suivre la progression de votre création sur le net, et en particulier vous souhaitez savoir combien de personnes en tout ont visionné votre vidéo au bout d'un certain nombre d'heures.
Vous êtes ami avec un employé de la NSA, ce qui vous permet d'obtenir une carte très détaillée de votre réseau social préféré, où vous voyez les liens entre chaque individu. Sitôt qu'un individu voit la vidéo, il la partage. Tous ses contacts la voient très exactement une heure après, puis la partagent immédiatement à leur tour, etc.
Vous êtes le point d'émission de la vidéo à l'heure 0, qui ira vers vos amis, puis les amis de vos amis… A partir du réseau social, vous souhaitez obtenir la liste triée des gens l'ayant vue, en fonction de l'heure.
Quel est le graphe ?
Bon là c'est assez explicite, un nœud pour chaque individu, et une arête pour chaque relation entre deux individus.
Ce graphe est :
1. cyclique
2. non orienté (l'amitié marche dans les deux sens normalement, mais si vous préférez un système avec des followers ce sera un graphe orienté)
3. non pondéré
4. pas forcément connexe car il est possible de trouver des communautés ou individus parfaitement isolés
5. creux (sauf quand tout le monde connait tout le monde, mais c'est rare).
On va donc, une fois de plus, utiliser une liste d'adjacence.
On veut obtenir la liste des nœuds en fonction de leur distance à un nœud particulier, le vôtre.
Le parcours en largeur
Le BFS est l'algorithme qui permet de parcourir tout les nœuds en fonction de leur distance à l'origine. Il explore les cartes par cercles concentriques de plus en plus grands. Il fonctionne sur tout type de graphe, cyclique ou non, orienté ou non, etc.
Le BFS procède de la façon suivante : il prend le premier nœud (distance 0), puis traite tout les nœuds qui sont à une distance de 1, puis tout les nœuds à une distance de 2, puis tout les nœuds à une distance de 3… et ainsi de suite.
On remarque très vite que les nœuds à une distance 1 de l'origine sont ses voisins, à une distance de 2 ce sont les voisins de ses voisins, à une distance 3 les voisins des voisins de ses voisins… de manière générale, un nœud à distance $n$ est : soit relié à des nœuds de distance $n-1$, soit des nœuds de distance $n$, soit des nœuds de distance $n+1$. Certainement pas plus : sinon il existerait un moyen plus rapide de rejoindre le nœud suivant; certainement pas moins, sinon le nœud courant aurait pu être atteint plus rapidement.
Si nous disposons de tout les nœuds à distance $n$, nous avons accès à tout les nœuds de distance $n+1$.
Dès le début on a accès au nœud de distance 0, donc en appliquant itérativement ce procédé on aura accès à tout les nœuds en fonction de leur distance à l'origine (s'ils sont connexes à elle).
Si vous ignorez ce qu'est une file FIFO, il n'est pas trop tard !
Voici l'algorithme :
- 1) Je prend le premier nœud de la file d'attente des nœuds à traiter.
- 2) Pour visiter ce nœud je le marque comme visité.
- 3) Je prend chacun de ses voisins non visités et je les ajoute à la fin de la file d'attente des nœuds à visiter
- 4) Je reprends le 1) tant qu'il reste des nœuds à traiter dans la file d'attente
Voici le pseudo code correspondant :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Procedure BFS(Graphe G, Noeud Origine)
{
File aTraiter
Marquer Origine comme visite
aTraiter.enfiler(Origine)
Tant que aTraiter.nonVide()
{
Noeud N = aTraiter.defiler()
Pour chaque voisin V de N
Si V non visite
Marquer V comme visite
aTraiter.enfiler(V)
}
}
|
Cet algorithme fonctionne, je vous le promet !
Il commence par enfiler l'origine à distance 0, puis tout les nœuds 1, puis pour chaque nœud à distance 1 il va enfiler d'autres nœuds à la distance 2 (à la suite des nœuds à distance 1 donc), puis il défilera les nœuds à distance 2 pour enfiler des nœuds à distance 3 à leur suite.
Ainsi les nœuds ne sont jamais mélangés : ils sont présents dans la file par "paquets" consécutifs qui correspondent à leur distance à l'origine.
Sur un arbre, il explore les nœuds en fonction de leur hauteur (distance à la racine) contrairement au DFS qui va effectuer toutes les descentes possibles de la racine à une feuille. Ainsi, l'ordre d'exploration des nœuds du graphe ci-dessous pourra être : A - B - C - E - D - F - G. Comme vous pouvez le constater, tout les nœuds frères sont parcourus les uns à la suite des autres, la racine étant l'origine du BFS.
Et que se passera-t-il si d'aventure nous remplacions la file par une pile ? On retrouve la version itérative du DFS présentée à la section précédente !
Il apparaît donc qu'il y a un lien important entre algorithme et structure de données. L'écriture sous forme itérative ou récursive dépend essentiellement de facteurs comme la lisibilité, la manière de laquelle l'algorithme s'explique le mieux, et enfin les performances.
Tout comme pour le DFS, la complexité en temps est en $O(N+A)$. Une fois encore la densité du graphe influe beaucoup sur les performances de l'algorithme.
La file peut contenir autant de nœuds que le graphe en possède, d'où une complexité en mémoire de $O(N)$. Le pire des cas concerne un graphe de diamètre très faible : la file est encombrée par la présence des nombreux nœuds à distance égale de l'origine.
Le BFS peut servir à détecter les composantes connexes d'un graphe (tout comme le DFS), si plusieurs appels à la fonction BFS() sont réalisés avec des origines différentes. Mais le BFS a un avantage sur le DFS lors de la recherche de composantes connexes : il trouve le plus court chemin entre ces deux nœuds (s'il existe) dans le cas d'un graphe non pondéré.
Dans le cas d'un graphe implicite de taille infini (ou de très très grande taille) le DFS risque de s'engager dans une mauvaise voie dans le début et de s'y enfoncer trop profondément, voir à l'infini ! Impossible de déterminer en un temps raisonnable (ou un temps fini) un chemin entre deux nœuds connexes, alors que le BFS va explorer plusieurs chemins possibles à la fois, ce qui lui donne l'assurance de trouver un jour ce chemin. Pour cette raison les graphes implicites de grande taille sont souvent parcouru par un BFS plutôt qu'un DFS.
Mais le BFS peut aussi servir à marquer les nœuds en fonction de leur distance à l'origine. C'est ce que nous allons voir tout de suite !
Le prix du succès
Une petite modification suffit à la résolution du problème.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | Procedure BFS(Graphe G, Noeud Origine)
{
File aTraiter
profondeur[Origine] = 0
Marquer Origine comme visite
aTraiter.enfiler(Origine)
Tant que aTraiter.nonVide()
{
Noeud N = aTraiter.defiler()
Afficher : N.nom + " voit la video a l'heure " + profondeur[N]
Pour chaque voisin V de N
Si V non visite
profondeur[V] = profondeur[N] + 1
Marquer V comme visite
aTraiter.enfiler(V)
}
}
|
Ci-dessous, vous pouvez voir l'effet de cet algorithme sur un graphe simple. Les nœuds sont marqués en fonction de leur ordre de visite par le BFS : le nœud n°1 correspond donc à l'origine. Les nœuds en cours de visite (c'est à dire présents dans la file) sont coloriés en bleu. Les nœuds déjà visités et extraits de la file sont coloriés en vert. Ici, tout les nœuds à distance 2 ou moins ont été explorés. Les nœuds à distance 3 sont en cours d'exploration. Le seul nœud à distance 4 n'a pas encore été traité.
Et voilà. Vous pouvez également indiquer le nombre total de gens ayant vu la vidéo à chaque heure, je vous laisse le coder vous même, ce n'est pas très difficile.
L'exhaustif et Uno
Connaissez-vous Uno$^{TM}$ ?
Comme nous l'explique si bien Wikipédia, c'est un jeu de carte américain créé en 1971 par Merle Robbins. Il est pourvu de pleins de règles subtiles et de cartes agressives pour faire rager les petits comme les grands.
Aujourd'hui, je ne vous propose pas de programmer ce célèbre jeu. A la place je vous propose plutôt de résoudre ce petit problème.
Dans Uno, chaque joueur possède un certain nombre de cartes en main, qui peuvent être de 4 couleurs : bleues, vertes, rouges ou jaunes.
Elles sont numérotées de 0 à 9.
Il existe également certaines cartes spéciales ("Joker", "Inversion", "Super Joker"…) mais nous ne y intéresserons pas ici, par soucis de simplicité.
Le jeu comporte un talon. On ne peut poser une carte sur le sommet de ce talon que si la carte au sommet du talon est :
- De même couleur que la carte qu'on joue
- De même valeur faciale que la carte qu'on joue
Un petit exemple :
- poser un 7 rouge sur un 9 rouge est autorisé
- poser un 4 vert sur un 4 bleu est autorisé
- poser un 2 jaune sur un 2 jaune est autorisé
- poser un 6 bleu sur un 3 vert est interdit
Il est ainsi possible d'empiler ces cartes de diverses façons en suivant ces règles, pour obtenir un talon plus ou moins haut.
Comme vous n'avez rien de mieux à faire, vous voulez savoir, à partir d'un ensemble de cartes donné, quels sont tout les talons qu'il est possible de réaliser avec. Les cartes qui ne pourront pas être ajoutées au talon seront éventuellement laissées sur le côté.
Vous pouvez empiler les cartes de votre choix dans n'importe quel ordre, tant que vous respectez les règles.

Exercice : vous commencez à le connaître par cœur normalement.
Quel est le graphe ? Quels sont ses caractéristiques ? Quelle question se pose-t-on sur lui ?
Correction :
Rappelez-vous : un graphe représente des objets et des relations entre ces objets.
Ici chaque objet, chaque nœud, est donc une carte. Les arêtes sont définies par une valeur faciale ou une couleur commune. C'est donc un bon exemple de graphe dans lequel les arêtes peuvent être déduites du nœud à partir de certaines règles de construction simples.
- Ce graphe est cyclique. Certes, on ne peut pas utiliser une même carte plus d'une fois, mais il y a plus d'une manière de poser une carte, qui aboutira à d'autres situations où il serait ensuite théoriquement valide de poser cette carte si elle n'avait pas déjà été jouée.
- Ce graphe est non orienté. L'ordre dans lequel sont empilés les cartes n'a pas d'importance, puisque les règles ne s'intéressent qu'à la relation d'adjacence de deux cartes, indépendamment de leur ordre.
- Ce graphe est non pondéré (sapristi, un de plus !).
- Une fois encore, ce graphe n'est pas nécessairement connexe. Il est parfois possible de former deux groupes de cartes n'ayant aucune couleur ou aucun numéro en commun.
Ce graphe est dense, selon moi. En effet il n'y a pas de caractérisation formelle entre un graphe dense et un graphe qui ne l'est pas, c'est laissé à l'appréciation de chacun. Laissez moi vous expliquer ma démarche.
En supposant que l'on ait beaucoup de cartes, disons $N$, et qu'elles soient toutes tirées au hasard : en moyenne nous aurons $\frac{N}{4}$ cartes de chaque couleur (car il y a 4 couleurs).
Toutes les cartes de même couleur seront au moins reliées entre elles. Donc, en moyenne, chaque carte sera reliées à au moins $\frac{N}{4}$ autres cartes.
Chaque carte est aussi reliée à un $\frac{1}{10}$ (car 10 chiffres) des cartes des 3 autres couleurs, soit $\frac{3\times N}{40}$ autres cartes en moyenne.
Cela fait une moyenne de $0,325\times N$ arêtes par nœud. Le degré de chaque nœud n'est pas constant : il dépend de $N$.
Ce qui porte le total à environ $0,162\times N^2$ arêtes, car c'est un graphe non orienté (il ne faut pas compter deux fois chaque arête).
Le nombre d'arêtes du graphe est fonction de $N^2$. On peut donc qualifier ce graphe de dense.
Et il est suffisamment dense pour rendre la matrice d'adjacence plus intéressante que la liste.
Voici le graphe associé à un ensemble de 20 cartes (5 de chaque couleur).
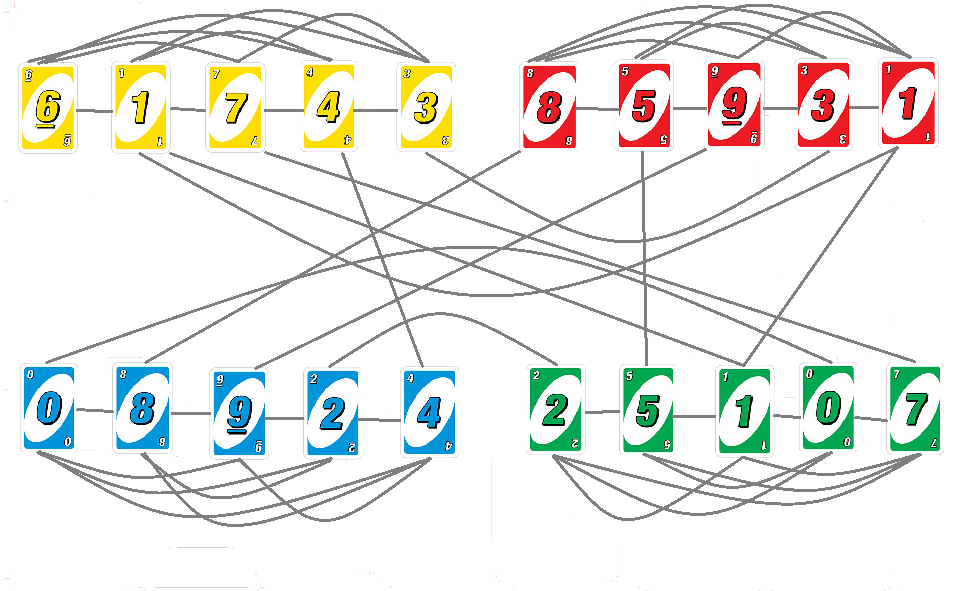
En théorie chaque carte devrait être reliée à elle même. Mais comme on ne peut pas utiliser deux fois la même carte (ce qui n'empêche pas celle-ci d'être présente en plusieurs exemplaires dans le jeu de départ), on sait d'avance que ces arêtes (qu'on nomme boucle) ne nous serviront pas. Autant les supprimer maintenant.
On souhaite connaître quels sont tout les talons possibles. Un talon est caractérisé par un ensemble de cartes dans un certain ordre. Et les contraintes d'adjacence de deux cartes sont celles des arêtes du graphe !
Par conséquent, chaque talon peut être représenté par un chemin du graphe : l'ordre de visite des nœuds et la taille du chemin suffit à définir le talon.
Pour générer tout les talons possibles, il faut donc générer tout les chemins du graphe !
L'exhaustif
Exhaustif : qui inclut tous les éléments possibles d’une liste, qui traite totalement un sujet.
Wiktionnaire
Nous cherchons une liste de tout les talons possibles, sans en oublier aucun. Il nous faut donc une liste exhaustive des talons possibles.
Cela nécessite un algorithme capable d'effectuer une énumération exhaustive de tout les chemins du graphe. D'où le nom "exhaustif".
Il faut trouver une méthode systématique pour dénombrer les chemins du graphe.
Comment procéderions-nous "à la main" ?
Par exemple, nous pourrions prendre une carte et l'ajouter au talon. Puis prendre une autre carte et l'ajouter au talon (en respectant les règles). Puis continuer à ajouter des cartes qu'il est possible d'en ajouter, sans réutiliser deux fois la même (évidemment).
Et lorsqu'on est bloqué ? Une retire une carte au sommet du talon et on met une autre à la place, et c'est reparti !
On continue d'ajouter des cartes jusqu'à ce qu'on soit forcé d'en retirer une au sommet pour la remplacer par une autre qui n'a pas déjà été posée à cette hauteur et avec ce talon spécifique en dessous.
Ainsi, à la fin, tout les talons auront été construits.
Vous avez remarqué ? Un talon est une pile, donc nous aurons sûrement affaire à une pile dans cet algorithme !
En voici le pseudo-code :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | Fonction listerChemins(Graphe G)
{
Chemin chemins[]
Pour chaque noeud N
autresChemins = exhaustif(G, N, cheminVide)
chemins.concatener(autresChemins)
Renvoyer chemins
}
Fonction exhaustif(Graphe G, Noeud N, Chemin C)
{
Marquer N comme utilise
C.ajouter(N)
Chemin chemins[]
chemins.ajouter(C)
Pour chaque voisin V de N
Si V inutilise
autresChemins = exhaustif(G, V, C)
chemins.concatener(autresChemins)
Marquer N comme inutilise
Renvoyer chemins
}
|
Sans grande surprise, ici, la pile est la pile d'appel. Mais une fois encore, cet algorithme peut être passé sous forme itérative si le besoin s'en fait sentir.
Cette fonction ressemble beaucoup à celle du DFS, à deux exceptions près.
Premièrement, elle retourne quelque chose : la liste des chemins.
Secondement, et c'est là le point le plus important : l'état d'un nœud n'est pas définitivement fixé. A l'entrée de la fonction le nœud est marqué comme "utilisé"; en revanche, à la sortie de la fonction, il est de nouveau marqué comme "inutilisé".
Ainsi, la fonction exhaustif va pouvoir traiter plusieurs fois le même nœud, ce qui est somme-toute logique puisque qu'un même nœud peut faire parti de plusieurs chemins distincts. L'importance de marquer un nœud comme utilisé durant son utilisation (comme les toilettes publiques à verrou coloré) est la même que celle du DFS : empêcher les appels récursifs infinis en bouclant dans un cycle.
Sur le graphe ci-dessous, après un appel sur le nœud A, l'ordre d’exploration des nœuds pourrait être : A - B - D - F - E - C - G - E - F - B - D.
Cela générerait les chemins suivants :
- A
- A - B
- A - B - D
- A - B - F
- A - B - F - E
- A - C
- A - C - G
- A - E
- A - E - F
- A - E - F - B
- A - E - F - B - D
Et cela juste avec le nœud A comme origine ! Je vous épargne les autres.
Comme vous pouvez le constater le nombre de chemins différents augmente très vite et atteint un nombre important, même sur un graphe de petite taille.
Ce qui nous amène tout de suite à une question épineuse : quelle est la complexité en temps et en mémoire de l'algorithme ?
Commençons par la complexité en temps.
Quel est le pire des cas ?
Le pire des cas serait un jeu de carte où toutes les cartes sont reliées entre elles (typiquement : toutes de même couleur), ce qui revient à travailler sur un graphe complet.
Ainsi, je dispose de $N$ choix pour le premier élément du talon. Puis de $N-1$ pour le second. Puis de $N-2$ pour le troisième, et ainsi de suite. Le nombre de talons possible est donc égal à $N \times (N-1) \times (N-2) \times ... \times 2 \times 1 = N!$
En fait, toutes les permutations de cartes sont possibles (puisque toutes les cartes peuvent être adjacentes). Et le nombre de permutations de $N$ éléments est bien égal à $N!$.
Cet algorithme est donc en $O(N!)$ en temps.
La fonction factorielle croit asymptotiquement plus vite que la fonction exponentielle. Pour cette raison, même sur des instances de petite taille, certains problèmes sont insolubles en un temps raisonnable.
Pour vous faire une idée, 20! = 2 432 902 008 176 640 000. Donc si le graphe ci-dessus était complet, il faudrait plusieurs dizaines de milliers d'années de calcul. Heureusement il ne l'est pas ! De mon côté j'ai trouvé 437 672 443 chemins différents (vous pouvez vérifier si l'envie vous en prend).
Quant à la complexité en mémoire, elle est nécessairement $O(N!)$ elle aussi, puisqu'il s'agit là du nombre de solutions.
Cependant, si vous n'aviez qu'à dénombrer les solutions (sans les produire), vous auriez alors un algorithme en $O(N)$, car la profondeur de récursion peut atteindre N nœuds.
La recherche exhaustive, bien que donnant des résultat exacts de par son exhaustivité, ne peut pas être utilisée en pratique pour tout les problèmes, à cause de sa lenteur.
Pour cette raison, de nombreux problèmes sont résolus avec des algorithmes donnant une réponse approchée (ou exacte mais dont on ne peut pas prouver qu'elle est exacte) qui ont une durée d'exécution plus courte. Ces algorithmes sont des sujets de recherche encore actifs qui mériteraient un tutoriel entier à eux seuls, donc nous n'en parlerons pas plus ici.