Lorsqu’on parle d’internationalisation d’un logiciel, la première chose qui vient à l’esprit est de lui permettre d’être multi-langues. Donc, attaquons cette partie.
- La sélection de la langue
- Différentes tailles de texte
- Le sens d'écriture
- Tout ce qui vient avec une langue mais qui n'était pas prévu
La sélection de la langue
La sélection de la langue, c’est le détail superimportant, qui a l’air simplissime… et qui est complètement raté dans la majorité des cas, y compris par les plus grands. Donc, s’il n’y a qu’une seule chose que vous devez retenir de ce tutoriel, c’est ça :
- L’utilisateur peut toujours choisir la langue qu’il veut parmi toutes celles disponibles.
- Le nom d’une langue est toujours dans la langue elle-même, jamais dans celle affichée.
- On utilise jamais de drapeau pour représenter une langue.
C’est le moment de détailler ces points, dont chacun d’eux peut rendre l’internationalisation de votre application inopérante.
L’utilisateur doit pouvoir choisir la langue d’affichage
Ça a l’air idiot, mais on ne compte plus les logiciels qui, bien que multilingues, forcent l’affichage dans une langue sur un critère imposé par le développeur. Le problème est surtout vrai pour les sites internet, qui par nature peuvent être accessibles de partout dans le monde.
Or, je peux très bien visiter une page web depuis la France, dans un navigateur réglé en français… et ne pas lire le français. Que le site me propose cette langue par défaut c’est une excellente idée, mais il doit me laisser le choix.
Le nom de la langue est dans la langue elle-même
Ici rien que de la simple logique, mais à laquelle il faut penser : dans le sélecteur de langues, et contrairement à tout le reste de l’interface, on ne s’adresse pas à quelqu’un qui parle la langue déjà sélectionnée (et qui aurait besoin de comprendre la liste complète des langues) mais à quelqu’un qui recherche une langue qu’il maitrise dans la liste (et donc qui a besoin de comprendre lesquelles sont disponibles.
C’est pourquoi les éléments de cette liste ne doivent jamais être traduits, et chaque nom de langue doit être donné dans la langue en question.
Un francophone a de grandes chances de sélectionner « french » dans une liste affichée intégralement en anglais ; mais combien comprendront qu’ils doivent choisir « 프랑스어 », « フランス語 », « Ֆրանսերեն », « Ranskan kieli », « ფრანგული ენა » ou encore « Французский язык » ?
Donc, si votre logiciel est disponible en français, anglais, russe et coréen, montrez « français, English, Русский, 한국어 » dans le sélecteur de langues, et ce quelle que soit la langue courante de l’application.
Un drapeau ne représente pas une langue
Un drapeau représente un état, une nation, une région… mais jamais une langue. Il y a un site entier sur le sujet (en anglais).
Ça n’est pas très naturel pour les Français qui comprennent français, parce que leur pays et leur langue partagent le même nom. Mais les contrexemples sont très nombreux dans les deux sens :
- Beaucoup de langues sont parlées dans plusieurs pays : le français est parlé en France, en Suisse, en Belgique, au Québec, en Afrique – d’où viennent beaucoup de lecteurs de Zeste de Savoir… Représenter le français par le drapeau de la France, c’est ignorer tous ces pays.
- Beaucoup de pays ont plusieurs langues officielles : la Belgique, la Suisse, le Canada… même l’Inde reconnait le français comme l’une de ses 22 langues régionales. Quelle langue désigne ces drapeaux ?
- Dans le cas d’une langue qui tient son nom d’un pays, le pays d’origine n’est pas toujours celui qui a le plus de locuteurs de cette langue. Devrait-on évoquer l’anglais par le drapeau d’Angleterre (que personne ne connait), du Royaume-Uni (qui est la source historique) ou des USA (qui a le plus d’usagers) ? L’espagnol doit-il être représenté par un drapeau d’Espagne ou du Mexique ? Le portugais par un drapeau du Portugal ou du Brésil ?
- Il y a des langues qui ne sont pas associées à un pays en particulier : quel drapeau représente l’arabe littéral, celui qui est généralement écrit ?
- Quid des émigrés ?
Donc, arrêtez de mettre des drapeaux pour désigner des langues. C’est au mieux une erreur, au pire une insulte.
Par contre, le drapeau reste un excellent moyen de sélectionner un pays ou une région, si par exemple certaines parties ne sont disponibles que dans une région donnée, ou que l’application gère les variantes locales d’une même langue (comme le français de France et du Canada).
(Promis, les sections suivantes sont plus courtes)
Différentes tailles de texte
Différentes langues, c’est aussi différentes tailles pour un même texte. Ça a un impact sur les éléments de design et la mise en page qui doivent être fluides pour éviter de se retrouver avec du texte qui déborde ou des composants presque vides.
On pense généralement à la longueur – l’anglais et l’italien sont d’ordinaire plus concis que le français qui lui-même est plus court que l’allemand.
On oublie plus souvent l’adaptation en hauteur nécessaire aux langues à alphasyllabaires ou à idéogrammes. Gérer ces langues (principalement asiatiques), c’est prendre en compte des textes beaucoup plus brefs, mais avec des lignes beaucoup plus hautes que leurs équivalents occidentaux. L’impact est surtout visible sur les éléments d’interface.
Le sens d'écriture
Toutes les langues ne s’écrivent pas de gauche à droite. Or, le sens de lecture de l’interface utilisateur est le même que celui du langage.
Lorsqu’on change de sens de langue, toute l’interface devrait s’inverser.
Pour mieux comprendre ce dont il s’agit, je vous laisse comparer la page d’accueil de Wikipedia en français et en arabe ; on y voit que tous les élément d’interface qui sont à gauche dans un idiome sont à droite dans l’autre, et vice-versa :
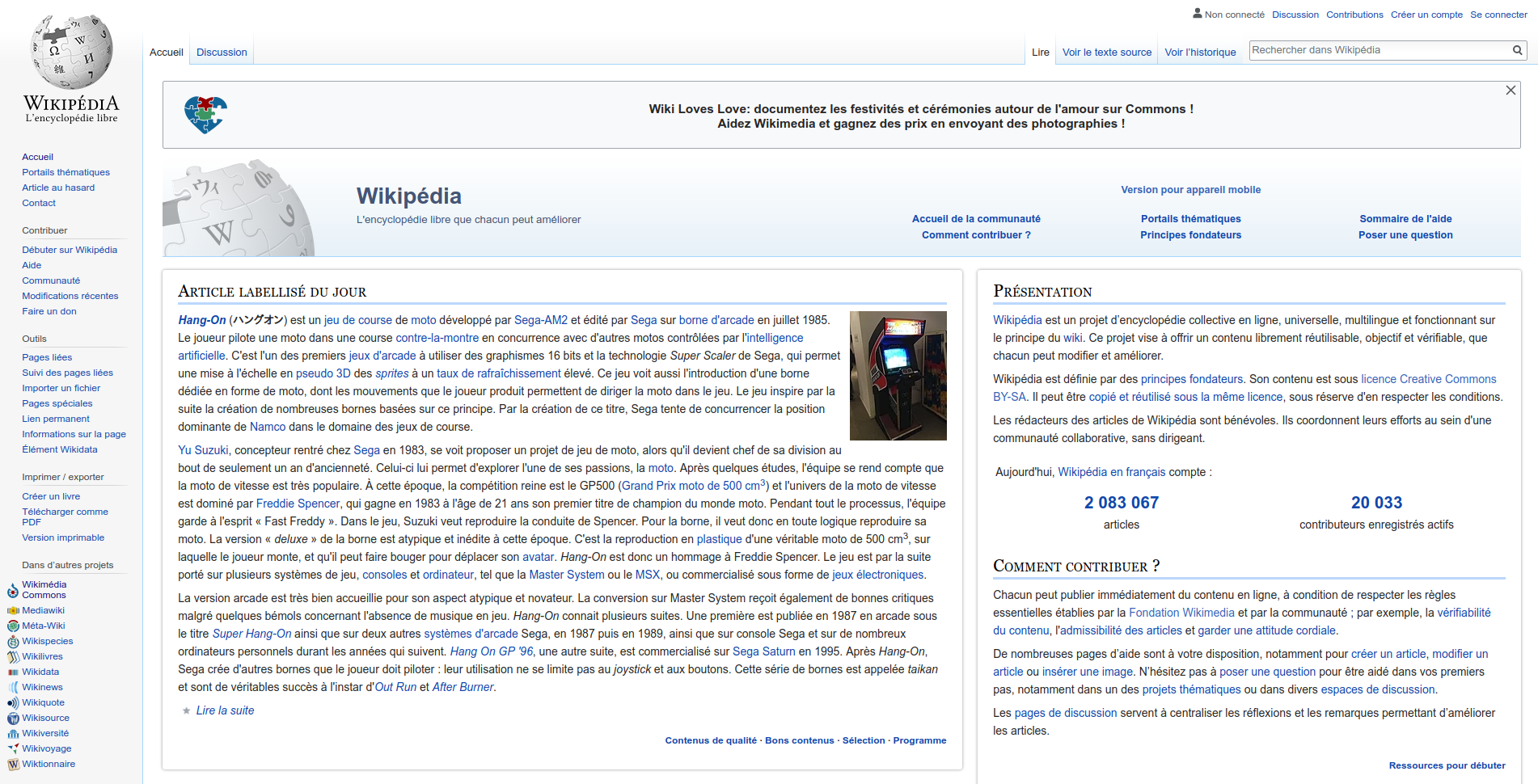
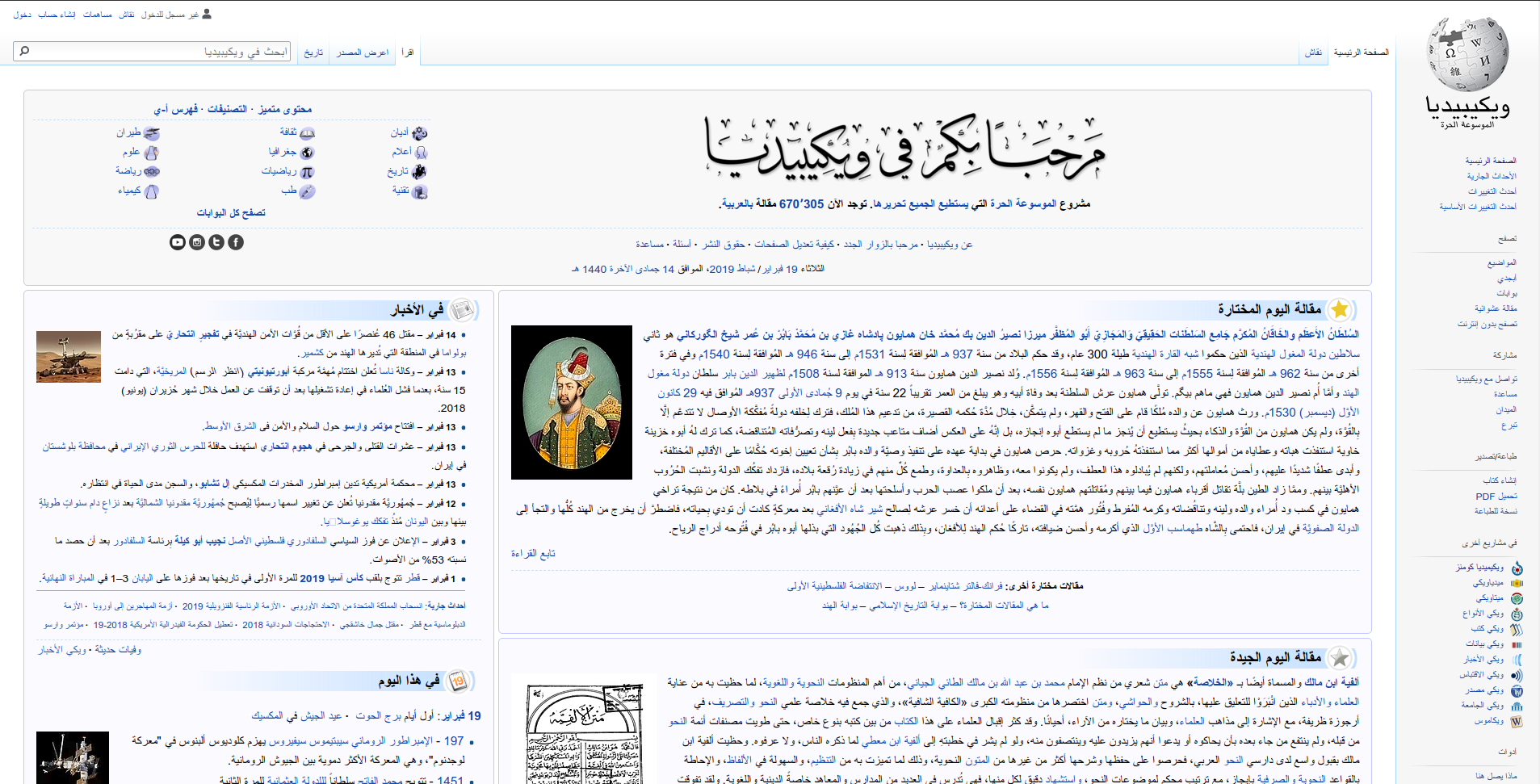
Notez que selon la technologie employée par votre logiciel, cette inversion peut être prévue et très facile (Android raisonnablement récent) ou au contraire horrible à réaliser (sites web sans framework qui prends déjà ce point en compte).
Tout ce qui vient avec une langue mais qui n'était pas prévu
Ah oui, parce qu’on n’y pense pas forcément, mais chaque langue vient avec ses petites spécificités qui peuvent casser des points que le développeur a considérés comme acquis et évidents.
Le cas du pluriel
Certains éléments peuvent s’afficher au singulier ou au pluriel selon les circonstances. Non seulement il faut prendre ce fait en considération ; mais surtout, les règles d’accord dépendent du langage.
Si le français fait usage du singulier et du pluriel (deux cas) d’autres langues ont des systèmes de nombres bien plus complets et complexes. Dans les cas « fréquents », on trouve une gestion spécifique du duel (deux éléments) et du paucal (quelques éléments).
L’accord de l’absence d’éléments dépend de la langue : certaines utilisent le singulier ; l’anglais le pluriel ; le français le concept flottant de « on met le nombre qui devrait être utilisé s’il y avait un nombre normal du truc absent »1 (bonne chance !).
Généralisation : le cas des accords, déclinaisons et autres spécificités
Plus généralement, toute clé de traduction à trous (du style {personnage} ramasse {objet}) peut se transformer en prise de tête et en gestion de cas particuliers. Parce que des cas spéciaux à gérer peuvent arriver :
- Si le genre du personnage impose un accord plus loin dans la phrase – c’est fréquent en français.
- Si le genre de l’objet impose une conjugaison propre – c’est fréquent en italien.
- Si l’objet impose une déclinaison spécifique selon le type d’objet – c’est fréquent en allemand, ou dans les langues extrême-orientales avec la notion de classificateur.
- Et on pourrait multiplier les exemples à l’infini.
Ici, pas de miracle : il faut trouver un équilibre entre « chaque variante a une clé de traduction spécifique » (ce qui donne des combinatoires ingérables) et « la traduction doit se débrouiller avec les clés qu’on lui fournit » (ce qui peut contraindre à des phrases vraiment pas naturelles). L’équilibre est en plus différent selon le type d’application : un framework technique se contentera très bien de traductions à la hache, tandis qu’un jeu vidéo narratif aura besoin d’un respect soigné des ambiances. C’est l’occasion pour l’équipe de développement de discuter avec celle de traduction, c’est souvent très enrichissant !
Gestion de la casse
Il se peut qu’un bout de votre application change la casse de certains textes. Déjà, la distinction entre majuscule et minuscules n’existe pas dans toutes les langues, et toutes les langues n’utilisent pas les mêmes règles sur ce qu’est la « bonne » casse2
Pire encore : changer la casse d’un mot peut donner un résultat différent selon la langue ! Je vous laisse imaginer les dégâts si vous comptiez sur cette modification d’un point de vue technique.
L’exemple typique est celui du I turc. Certaines langues (à commencer par le turc) ont deux lettres i : avec et sans point i et ı, qui se capitalisent respectivement en İ et I. Donc, si la langue courante est une de ces langues, id va devenir İD, ou ID va devenir ıd après un changement de casse… alors que le développeur attendait respectivement ID ou id.
Gestion des diacritiques
Ceci nous amène à la problématique plus générale des diacritiques(ces symboles qu’on rajoute aux lettres, comme les accents). Le principe est simple :
On ne supprime jamais les diacritiques. Il n’y a plus de raison de faire ça3.
En français, on arrive généralement à saisir le sens d’un texte privé de ses accents, et les lettres accentuées ne sont pas considérées comme différentes de leurs variantes nues ; mais c’est très loin d’être le cas dans toutes les langues.
Quant aux notions de slug et autres bizarreries qu’on trouve par exemple dans les URL : vous avez un souci d’encodage et non de diacritiques. Wikipedia est l’un des plus gros sites au monde et emploie les signes de toutes les langues dans ses URL – vérifiez par vous-même.
Si votre crainte (légitime) est qu’un utilisateur abuse de votre largesse en employant des caractères différents, mais visuellement identiques (comme les Α grec, А cyrillique et A latins), ce n’est pas un problème de diacritique, mais d’homoglyphes et Unicode fournit les outils pour les résoudre.
Ordre alphabétique
L’ordre alphabétique dépend de l’alphabet utilisé (y compris au sein d’un même groupe d’alphabets, par exemple tous les alphabets « latins »). C’est à prendre en compte si vous ne voulez pas perdre vos usagers.
- Typiquement en alimentation : sans sel (il y a normalement du sel au singulier), mais sans sucres (il y a normalement des sucres alimentaires, au pluriel). Et encore, cette règle est discutée…↩
- L’allemand colle des majuscules aux noms communs. L’anglais américain fait des titres avec une majuscule à chaque mot, ce qui ne se fait pas du tout en français. Etc.↩
- …sauf si vous devez vous interfacer avec un antique système. Mais là c’est l’occasion de 1. vérifier que ce système ne peut pas être mis à jour et 2. de faire un projet dédié, avec étude d’impacts, et tout.↩
Ainsi donc, gérer les langues dans son logiciel, c’est bien plus que permettre d’afficher des traductions. Ça nécessite :
- Un sélecteur de langues, avec chaque nom de langue dans sa langue elle-même et non représenté par un drapeau.
- Une ergonomie qui accepte des textes de diverses tailles, en longueur comme en hauteur.
- Une organisation de l’espace qui suit le sens de lecture de la langue choisie.
- … et plein de détails spécifiques à chaque langue, comme les pluriels, les accords, la casse, l’ordre alphabétique et j’en passe.
Il est maintenant temps de s’attaquer aux différences culturelles – car oui, elles ont aussi un impact technique.