Au fil de cette partie nous allons explorer des fonctionnalités plus avancées de sqlite3 : comment gérer les exceptions, ajouter ses propres types de données ou encore créer une copie sauvegardée.
- Gérer les exceptions
- Utiliser ses propres fabriques
- Ajouter ses propres types
- Créer une copie sauvegardée
- Simplifier son code
Gérer les exceptions
Lors de notre utilisation de sqlite3, nous pouvons rencontrer des exceptions.
Mécanismes de gestion des erreurs
Celles-ci se gèrent comme il est coutume de faire en Python (try ... except ... finally ...) :
import sqlite3
connexion = sqlite3.connect('basededonnees.db')
curseur = connexion.cursor()
curseur.execute("""CREATE TABLE IF NOT EXISTS livres(
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE,
titre TEXT,
nombre_pages INTEGER
)""")
# Insertion données avec erreur d'intégrité puis sans
try:
donnees = (
{"id": 1, "titre": "Les Raisins de la colère", "nombre_pages": 640},
{"id": 1, "titre": "Rhinocéros", "nombre_pages": 246},
)
curseur.executemany(
"INSERT INTO livres (id, titre, nombre_pages) VALUES (:id, :titre, :nombre_pages)",
donnees
)
connexion.commit()
except sqlite3.IntegrityError:
print("Erreur d'intégrité") # Affichage "Erreur d'intégrité"
connexion.rollback()
curseur.executemany(
"INSERT INTO livres (titre, nombre_pages) VALUES (:titre, :nombre_pages)",
donnees
)
connexion.commit()
print(curseur.rowcount) # Affichage "2"
connexion.close()
Erreurs disponibles
Voici un listing des classes d’erreur disponibles :
| Classe d’erreur | Classe parente | Description |
|---|---|---|
| sqlite3.Warning | Exception | Une exception pouvant être levée par d’autres modules utilisant sqlite3 |
| sqlite3.Error | Exception | L’exception de base pour toutes les autres exceptions du module |
| sqlite3.InterfaceError | sqlite3.Error | Exception levée en cas d’erreur en lien avec l’utilisation de l’API C de SQLite |
| sqlite3.DatabaseError | sqlite3.Error | Exception levée en cas d’erreur en lien avec la BDD |
| sqlite3.DataError | sqlite3.DatabaseError | Exception levée en cas d’erreur en lien avec les valeurs des données traitées (texte trop long par exemple) |
| sqlite3.OperationalError | sqlite3.DatabaseError | Exception levée en cas d’échec d’opération sur la BDD (tentative d’écriture dans une BDD en lecture seule par exemple) |
| sqlite3.IntegrityError | sqlite3.DatabaseError | Exception levée en cas d’erreur en lien avec l’intégrité des données (clef primaire déjà existante par exemple) |
| sqlite3.InternalError | sqlite3.DatabaseError | Exception levée par la bibliothèque SQLite en cas de dysfonctionnement interne |
| sqlite3.ProgrammingError | sqlite3.DatabaseError | Exception levée en cas d’erreur de programmation (mettre plusieurs requêtes SQL dans la méthode execute par exemple) |
| sqlite3.NotSupportedError | sqlite3.DatabaseError | Erreur levée en cas d’opération non supportée par le bibliothèque SQLite sous-jacente |
L’objet sqlite3.Error possède deux attributs pour en apprendre plus sur l’erreur (sqlite_errorcode pour le code d’erreur et sqlite_errorname pour le nom de l’erreur).
Dans la documentation, il est parfois précisé les exceptions pouvant être levées pour certaines méthodes.
Utiliser ses propres fabriques
La bibliothèque met à disposition des moyens d’élaborer ses propres fabriques.
Fabrique de ligne
De base, sqlite3 présente une ligne de donnée lue sous forme de tuple.
Nous pouvons personnaliser ce comportement avec une fabrique de ligne (row factory). En effet, un objet de type Connection ainsi qu’un objet de type Cursor possèdent tous les deux un attribut row_factory dans ce sens. Il est alors préférable d’utiliser l’objet de type Connection si nous voulons que tous les curseurs créés par la suite soient impactés.
Classe Row
Nous pourrions vouloir accéder aux données via des clefs.
Justement, il y a une classe Row pour cela. Avec celle-ci, les données lues sont accessibles par positions ainsi que par clefs (peu importe la casse d’ailleurs). Il y a même une méthode keys.
import sqlite3
connexion = sqlite3.connect('basededonnees.db')
# Utilisation de la classe Row pour la fabrique de ligne
connexion.row_factory = sqlite3.Row
curseur = connexion.cursor()
curseur.execute("SELECT * FROM livres")
ligne = curseur.fetchone()
print(ligne[1]) # Affiche "Les Raisins de la colère"
print(ligne.keys()) # Affiche "['id', 'titre', 'nombre_pages']"
print(ligne['tItrE']) # Affiche "Les Raisins de la colère"
connexion.close()
Fonction personnalisée
Nous pourrions vouloir obtenir la ligne sous forme de dictionnaire ou autre. Il suffit alors de créer une fonction, prenant le curseur et les données, qui va formater la ligne comme voulue, puis de l’associer à l’attribut row_factory :
import sqlite3
# Définition fonction pour fabrique de ligne
def dict_factory(curseur, ligne):
noms_colonnes = [colonne[0] for colonne in curseur.description]
return {key: value for key, value in zip(noms_colonnes, ligne)}
connexion = sqlite3.connect('basededonnees.db')
# Utilisation de la fonction définie pour la fabrique de ligne
connexion.row_factory = dict_factory
curseur = connexion.cursor()
curseur.execute("SELECT * FROM livres")
ligne = curseur.fetchone()
print(type(ligne)) # Affiche "<class 'dict'>"
print(ligne) # Affiche "{'id': 1, 'titre': 'Les Raisins de la colère', 'nombre_pages': 640}"
connexion.close()
Fabrique de texte
Dans la première partie de ce cours, nous avons dit que la correspondance pour un texte SQL était une chaine str par défaut. Nous avons la possibilité d’interférer dans cette transposition via une fabrique de texte (text factory).
Cela est parfois nécessaire. En effet, cette correspondance fonctionne bien dans le cas d’un encodage utf-8, mais ce n’est pas toujours le cas quand la base de données utilise d’autres encodages comme expliqué dans la documentation.
L’objet de type Connection possède un attribut text_factory pour gérer cela :
# Fabrique de texte via fonction
connexion.text_factory = lambda valeur_texte: str(
valeur_texte,
encoding="utf-8",
errors="gestion_erreur"
)
Ajouter ses propres types
En plus des correspondances de base, il est possible d’ajouter des adaptateurs pour convertir ses propres valeurs dans un type accepté par SQLite, mais aussi des convertisseurs pour l’opération inverse.
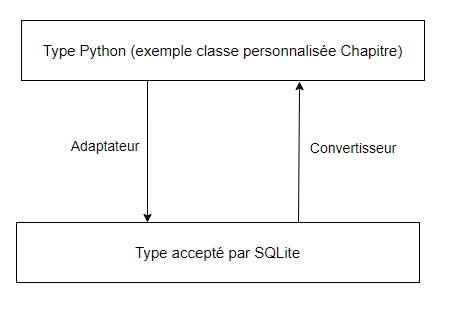
La documentation liste quelques exemples concernant les dates notamment.
Pour les besoins de cette section, nous commençons par créer notre classe.
class Chapitre:
def __init__(self, numero, titre):
self.numero, self.titre = numero, titre
Écriture en base avec adaptateur
Maintenant, nous allons ajouter une table en faisant simple :
curseur.execute("""CREATE TABLE IF NOT EXISTS chapitres(
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE,
chapitre TEXT
)""")
Pour adapter notre objet à un type supporté par SQLite (d’un objet chapitre à un TEXT ici), il y a deux possibilités.
Utiliser un objet qui s’adapte
La première consiste à faire en sorte que l’objet soit adaptable en lui implémentant une méthode spéciale __conform__. Cette méthode doit vérifier que le protocole fourni en paramètre est bien sqlite3.PrepareProtocol pour retourner une valeur d’un type accepté par SQLite :
class Chapitre:
def __init__(self, numero, titre):
self.numero, self.titre = numero, titre
# Implémentation de la méthode spéciale __conform__
def __conform__(self, protocol):
if protocol is sqlite3.PrepareProtocol:
return f"{self.numero};{self.titre}"
curseur.execute("INSERT INTO chapitres(chapitre) VALUES (?)", (Chapitre(1, "Préface"), ))
connexion.commit()
curseur.execute("SELECT * FROM chapitres ORDER BY id DESC LIMIT 1")
print(curseur.fetchone()) # Affiche "(1, '1;Préface')"
connexion.close()
Enregistrer une fonction d’adaptation
La seconde possibilité est de d’abord créer une fonction prenant l’objet et faisant cette conversion. Puis ensuite d’enregistrer celle-ci avec la fonction register_adapter du module en indiquant la classe et la fonction d’adaptation :
class Chapitre:
def __init__(self, numero, titre):
self.numero, self.titre = numero, titre
# Définition d'une fonction d'adaptation
def adapt_chapitre(chapitre):
return f"{chapitre.numero};{chapitre.titre}"
# Enregistrement de la fonction d'adaptation
sqlite3.register_adapter(Chapitre, adapt_chapitre)
curseur.execute("INSERT INTO chapitres(chapitre) VALUES (?)", (Chapitre(20, "Mot de fin"), ))
connexion.commit()
curseur.execute("SELECT * FROM chapitres ORDER BY id DESC LIMIT 1")
print(curseur.fetchone()) # Affiche "(2, '20;Mot de fin')"
connexion.close()
Lecture de base avec convertisseur
Au contraire, pour construire un type personnalisé à partir d’un type SQLite, il faut passer par un convertisseur.
Fonction de conversion
C’est un peu le même principe qu’avec une fonction d’adaptation. Nous devons créer une fonction qui va convertir l’objet de type bytes passé en un objet personnalisé voulu puis le retourner.
Il faut ensuite enregistrer cette fonction définie via register_converter en indiquant un nom sous forme de chaîne de caractères et la fonction.
# Définition d'une fonction de conversion
def convert_chapitre(s):
valeurs = s.split(b";", 1)
return Chapitre(int(valeurs[0]), valeurs[1].decode("utf-8"))
# Enregistrement de la fonction de conversion
sqlite3.register_converter("chapitre", convert_chapitre)
Détection de type
Pour que cela fonctionne, il faut également paramétrer la détection de type au niveau de l’objet de type Connection (désactivé par défaut).
Le constructeur de celui-ci peut prendre une valeur detect_types, soit PARSE_DECLTYPES (l’indication de conversion se fait au niveau du type déclaré dans la table), soit PARSE_COLNAMES (l’indication de conversion se fait au niveau du nom de colonne), soit les deux séparés par une barre verticale (dans ce cas-là c’est PARSE_COLNAMES qui prend la priorité).
PARSE_DECLTYPES
Avec la constante PARSE_DECLTYPES de sqlite3, nous indiquons la conversion de type au niveau de la création de la table. Ce nom de type doit correspondre avec le nom utilisé pour l’enregistrement de la fonction bien entendu.
Voici un exemple complet :
import sqlite3
# Connexion en renseignant detect_types à sqlite3.PARSE_DECLTYPES
connexion = sqlite3.connect('basededonnees.db', detect_types=sqlite3.PARSE_DECLTYPES)
curseur = connexion.cursor()
class Chapitre:
def __init__(self, numero, titre):
self.numero, self.titre = numero, titre
def adapt_chapitre(chapitre):
return f"{chapitre.numero};{chapitre.titre}"
def convert_chapitre(s):
valeurs = s.split(b";", 1)
return Chapitre(int(valeurs[0]), valeurs[1].decode("utf-8"))
sqlite3.register_adapter(Chapitre, adapt_chapitre)
sqlite3.register_converter("chapitre", convert_chapitre)
# Création de la table en indiquant le type pour la conversion
curseur.executescript("""
DROP TABLE IF EXISTS chapitres;
CREATE TABLE chapitres(
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE,
chap chapitre
);
""")
curseur.execute("INSERT INTO chapitres(chap) VALUES (?)", (Chapitre(20, "Mot de fin"), ))
curseur.execute("SELECT chap FROM chapitres")
chapitre = curseur.fetchone()[0]
print(chapitre.numero, chapitre.titre) # Affiche "20 Mot de fin"
connexion.close()
PARSE_COLNAMES
Avec la constante PARSE_COLNAMES de sqlite3, nous indiquons la conversion de type au niveau d’utilisation de la colonne de la table via la syntaxe nom_colonne AS 'nom_colonne [nom_conversion]'. Ce nom de type doit correspondre avec le nom utilisé pour l’enregistrement de la fonction bien entendu.
Voici un exemple complet :
import sqlite3
# Connexion en renseignant detect_types à sqlite3.PARSE_COLNAMES
connexion = sqlite3.connect('basededonnees.db', detect_types=sqlite3.PARSE_COLNAMES)
curseur = connexion.cursor()
class Chapitre:
def __init__(self, numero, titre):
self.numero, self.titre = numero, titre
def adapt_chapitre(chapitre):
return f"{chapitre.numero};{chapitre.titre}"
def convert_chapitre(s):
valeurs = s.split(b";", 1)
return Chapitre(int(valeurs[0]), valeurs[1].decode("utf-8"))
sqlite3.register_adapter(Chapitre, adapt_chapitre)
sqlite3.register_converter("chapitre", convert_chapitre)
curseur.executescript("""
DROP TABLE IF EXISTS chapitres;
CREATE TABLE chapitres(
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE,
chap
);
""")
curseur.execute("INSERT INTO chapitres(chap) VALUES (?)", (Chapitre(20, "Mot de fin"), ))
# Requête en indiquant le type de colonne pour la conversion
curseur.execute("SELECT chap AS 'chap [chapitre]' FROM chapitres")
chapitre = curseur.fetchone()[0]
print(chapitre.numero, chapitre.titre) # Affiche "20 Mot de fin"
connexion.close()
Remarquons que dans ce cas, nous n’avons même pas à spécifier de type lors de la création de la table pour les colonnes à convertir.
Que se passe-t-il si l’objet chapitre contient des caractères spécifiques à SQL ? Est-ce qu’il y a un risque d'injection SQL ? 
Je vous rassure : non ! Comme nous utilisons le système de placeholders de la bibliothèque (les fameux ? dans la requête SQL sont une approche possible), le pilote va se charger de protéger notre requête des injections.
Créer une copie sauvegardée
Il peut être judicieux voire nécessaire d’effectuer des sauvegardes.
Dans un fichier SQL
La méthode iterdump de notre objet de connexion permet de parcourir la base de données et d’en extraire la représentation SQL, ligne par ligne, à écrire dans un fichier :
# Exemple dump avec connexion.iterdump()
with open('dump.sql', 'w') as f:
for ligne in connexion.iterdump():
f.write('%s\n' % ligne)
Les instructions SQL du fichier pourront ensuite être utilisées pour recréer l’état de la base par exemple.
Dans une autre base de données
Pour faire un copier-coller dans une autre base directement, nous pouvons utiliser la méthode backup d’un objet de type Connection. Nous devons lui fournir une connexion vers la destination.
# Backup d'une BDD source vers une BDD destination
source = sqlite3.connect('basededonnees.db')
destination = sqlite3.connect('backup.db')
source.backup(destination)
destination.close()
source.close()
Il est possible de passer des valeurs pour choisir le pas de page à copier au fur et à mesure (page) ou encore avoir un retour de la progression au fur et à mesure (progress).
Simplifier son code
Découvrons maintenant quelques autres façons d’utiliser la connexion.
Se passer d’un curseur
En faisant appel directement aux méthodes d’exécution depuis un objet de connexion, les curseurs sont implicitement créés et retournés sans devoir le faire explicitement :
import sqlite3
connexion = sqlite3.connect(":memory:")
# Exécution via la méthode de l'objet de connexion directement
connexion.executescript("""CREATE TABLE IF NOT EXISTS livres(
id INTEGER PRIMARY KEY AUTOINCREMENT UNIQUE,
titre TEXT,
nombre_pages INTEGER
)""")
donnees = (
{"titre": "Les Raisins de la colère", "nombre_pages": 640},
{"titre": "Rhinocéros", "nombre_pages": 246},
)
connexion.executemany(
"INSERT INTO livres (titre, nombre_pages) VALUES (:titre, :nombre_pages)",
donnees
)
# Itération via le curseur implicite
for ligne in connexion.execute("select * from livres"):
print(ligne)
# (1, 'Les Raisins de la colère', 640)
# (2, 'Rhinocéros', 246)
connexion.close()
Choisir ou non l’auto-validation
Depuis la version 3.12 de Python, sqlite3 recommande de gérer les transactions en renseignant autocommit de la connexion à False. Il y a soit True, soit False, soit sqlite3.LEGACY_TRANSACTION_CONTROL (qui est la valeur par défaut historique).
C’est donc assez nouveau et il est prévu que la valeur par défaut passe de sqlite3.LEGACY_TRANSACTION_CONTROL à False dans une version ultérieure du module.
import sqlite3
con = sqlite3.connect("basededonnees.db", autocommit=False) # False recommandé à partir de Python 3.12
Qu’est-ce que cela change ?
En l’état, pas grand chose entre sqlite3.LEGACY_TRANSACTION_CONTROL et False. Le module gère les transactions et il faut valider (au risque de perdre ses modifications à la fermeture de la connexion) ou annuler ses modifications explicitement.
Avec True, les méthodes commit et rollback n’ont aucun effet : les modifications sont validées au fur et à mesure automatiquement.
Utiliser le gestionnaire de contexte
Un objet de type Connection peut être utilisé avec le gestionnaire de contexte with.
Avec l’auto-validation désactivée, cela permet, une fois la fin du corps du gestionnaire de contexte atteint, de valider si tout se passe bien ou au contraire d’annuler si erreur puis d’ouvrir une nouvelle transaction. Le tout de manière automatique.
import sqlite3
# Auto-validation désactivée (recommandé à partir de Python 3.12)
connexion = sqlite3.connect("basededonnees.db", autocommit=False)
try:
with connexion:
connexion.execute(
"INSERT INTO livres (titre, nombre_pages) VALUES (:titre, :nombre_pages)",
{"titre": "Le Petit Prince", "nombre_pages": 93}
)
# Si aucune erreur alors commit() automatique et ouverture d'une nouvelle transaction
# Si erreur alors rollback() automatique et ouverture d'une nouvelle transaction
except sqlite3.Error as e:
print(e.sqlite_errorcode, e.sqlite_errorname)
connexion.close()
Voilà, vous connaissez maintenant des usages plus avancés de sqlite3 !