
Bonjour tout le monde,
Maintenant qu'on a un site ouvert au public, on va devoir songer à mettre en place un système de mise à jour du site qui réponde à nos nouvelles contraintes :
- Fiable. On a déjà expérimenté la mise en prod qui provoque plein de régressions, l'idéal serait qu'elle ne revienne pas.
- Invisible pour les membres ou presque, en terme de coupure d'accès.
Un peu de contexte
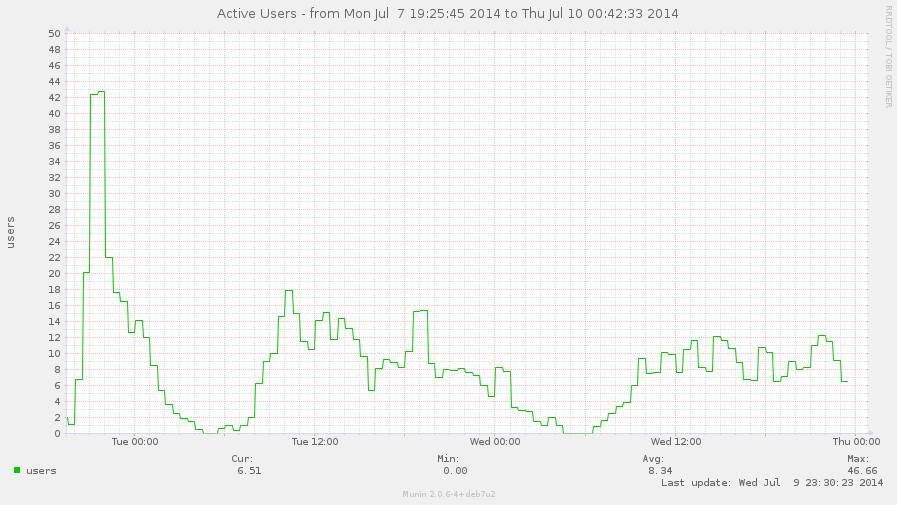
On ne s'en rends peut-être pas compte, mais on a déjà un site qui a une activité certaine. Deux jours après l'ouverture publique, bien qu'en bêta, on ne peut pas se permettre de gérer le site comme un petit blog personnel.
Actuellement, Zeste de Savoir, c'est :
- 250 inscrits
- 36 000 pages vues depuis l'ouverture publique
- 6/8 membres présents en permanence sur le site la journée
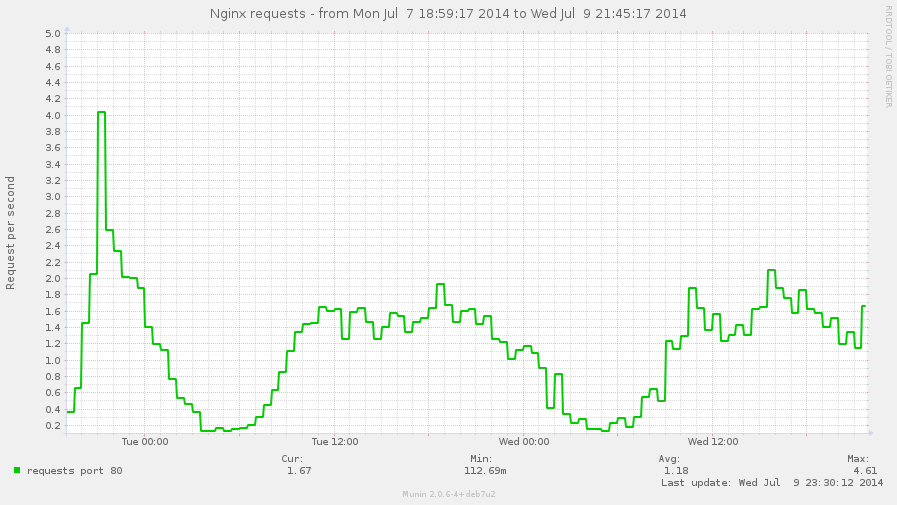
- Plus d'un hit/seconde en permanence sur notre Nginx la journée
Alors certes, on a un beau potentiel de croissance, mais on est déjà loin au-dessus des 20 visites / jour qui font la joie du blogueur amateur !
De plus, pour des raisons historiques, la majorité de nos visiteurs ont conscience des problèmes de qualité, de releases-à-régressions et de prod HS. Et ils nous le font savoir.
Exemple : hier je mettais en place une surveillance de Gunicorn. Un truc qui aurait dû couper le serveur pendant 2 secondes, mais qui n'a pas marché du premier coup suite à un problème de configuration entre la préprod et la prod. Ça a coupé le serveur pendant 2x 2 minutes, et 1x 2 secondes ensuite.
Eh bien en moins de 5 minutes de coupures cumulées, et alors qu'on est encore en bêta, on a eu un rapport de bug de plusieurs personnes et une taquinerie sur Twitter.
Workflow proposé
Worflows valables sauf hotfix urgents, évidemment.
Général (après la v1.0)
À un moment M, on décide qu'on a suffisamment de matière pour mettre en production quelque chose, i.e. faire une version N Dès lors :
- On gèle l'ensemble des fonctionnalités à mettre en prod, c'est-à-dire qu'on merge dev sur master, notre branche de release.
- La branche de relase ne reçoit plus que des correctifs. Les nouvelles fonctionnalités seront sur la version N+1 et vont sur dev.
- La pré-prod est mise à jour avec master aussi souvent que nécessaire. On vérifie sur la préprod, et pendant un temps suffisamment long, que tout fonctionne correctement, que les détails sont là, qu'on a rien oublié et qu'on a rien cassé.
Ceci n'est pas redondant avec la QA, parce que là on teste bien l'ensemble du site et non une fonctionnalité précise.
On pourrait imaginer ouvrir cette pré-production à des personnes tierces, selon les besoins. - Une fois qu'on ne trouve plus de problèmes sur la pré-prod, on met en prod, ce qui implique 3 sous-étapes :
- On taggue la version qui va en prod.
- On merge master dans prod (logique) mais aussi dans dev (pour faire remonter les corrections suite aux tests en pré-prod)
- On fait la MEP proprement dite.
- C'est prêt, on communique sur les nouvelles fonctionnalités !
Adaptation pour la bêta publique
Pour l'instant on est en bêta publique, ce qui implique qu'on a beaucoup de travail à faire et des membres qui sont – j'espère ! – prêts à être plus tolérants avec les trucs bizarres sur le site. Ce qui ne nous autorise pas à faire n'importe quoi.
Pour essayer de faire le tri dans tout ça, on a présentement 4 milestones :
- Version RCx : les trucs à faire le plus vite possible et à mettre en production rapidement.
- Version 1.0 : les trucs à faire pour la v1.0, i.e. le 21 juillet.
- Version 1.x : les trucs qui peuvent attendre après la sortie de la v1.0, mais qu'il ne faudra pas trop trop tarder à faire.
- Version 2.x : les lettres au Père Noël, qui regroupent des tas de bonnes idées mais absolument pas prioritaires.
Au niveau des mises en prod elles-mêmes, la milestone RCx a une date pour ce WE, ce qui ne veut pas dire qu'il faut attendre ce WE pour mettre en prod.
Voici ce que je propose :
- Une mise en prod rapide, au moins pour gérer les bugs qui nous sont remontés mais qui sont déjà corrigés.
- Une mise en prod tous les 2 à 3 jours, en passant par la pré-prod à chaque fois, pour nous garantir un minimum de stabilité dans ce qu'on diffuse. Parce que c'est le rush, le moment où tout le monde développe très vite, et que c'est exactement à ce moment qu'on a tendance à oublier des cas pathologiques.
Concernant la gestion de ces MEP, on allègerais aussi :
- Pas de merges.
- Un tag à chaque mise en prod, à la fois pour savoir ce qui est vraiment parti en prod (ça peut servir pour comprendre un bug) et pour afficher un numéro de version lisible à nos utilisateurs.
Qu'en pensez-vous ?









{kind=link}
{kind=link}